
OpenCost 规范是一套 供应商中立(vendor-neutral) 的方法,用于在 Kubernetes 环境中计量与分摊基础设施与容器成本。
1.Introduction
Kubernetes 使得容器化工作负载能够以复杂的方式进行部署,这些工作负载通常具有 短暂性(transient) 并且会消耗 不确定且变化的资源。虽然这让团队能够构建面向各种技术问题的强大解决方案,但同时也导致了一个问题:
在共享K8S环境中,如何衡量工作负载及其基础设施的资源使用与成本。
随着一个组织内部对Kubernetes的采用增长,这个问题会成为一个关键的业务挑战。在本文档中,我们定义了一种与供应商无关(vendor-agnostic) 的方法,用于准确测量并将 Kubernetes 集群的成本分配给其租户。
2.Foundational definitions
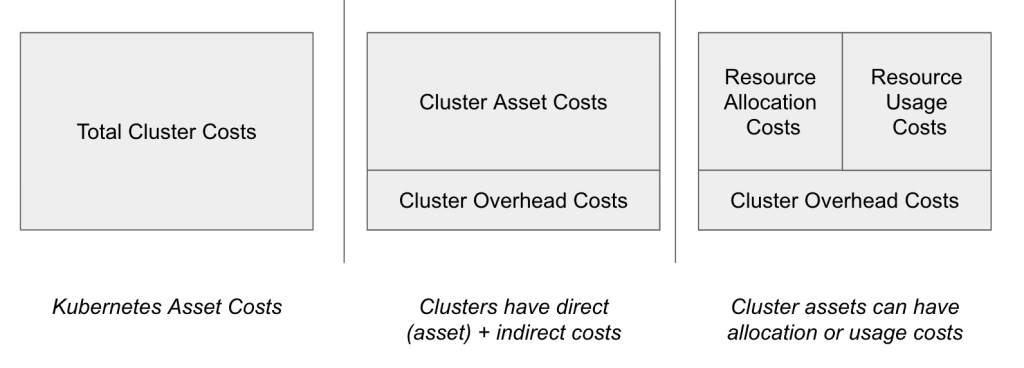
Total Cluster Costs(集群总成本)
代表运行一个 Kubernetes 集群所需的所有成本。
Cluster Asset Costs(集群资源资产成本)
指那些与集群内可观察的资源实体相关的成本,包括:
- 节点(Nodes)
- 持久卷(Persistent Volumes)
- 附加磁盘(Attached Disks)
- 负载均衡器(Load Balancers)
- 网络 ingress/egress 成本
从财务角度看,这些相当于销售成本(COGS)。
Cluster Overhead Costs(集群管理开销成本)
指为了运营所有这些 Asset 所需的间接成本,例如:
- 集群管理费用(Cluster Management Fees)
这相当于财务中的 SG&A(销售、管理与行政费用) / 间接费用。
| Total Cluster Costs | = | Cluster Asset Costs | + | Cluster Overhead Costs |
Cluster Asset Costs 再细分为:
| 类别 | 含义 |
|---|---|
| Resource Allocation Costs(资源分配成本) | 按资源“预留时长”收费,如 CPU 按小时计费。 |
| Resource Usage Costs(资源使用成本) | 按实际单位使用量计费,如每 GB 出网费用。 |
例如:
Node 成本 = CPU 成本 + GPU 成本 + 内存 RAM 成本 + 节点网络成本
| Total Cluster Costs | = | Resource Allocation Costs (for all assets) | + | Resource Usage Costs (for all assets) | + | Cluster Overhead Costs (for cluster) |
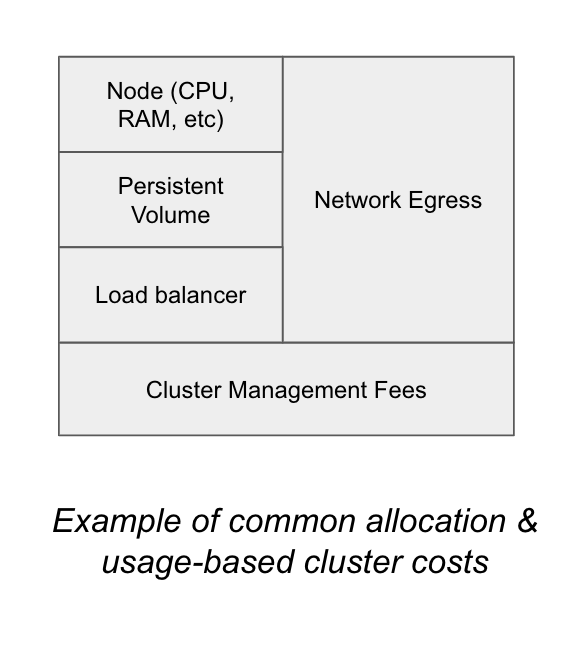
虽然不同环境的计费方式可能不一样,但下面是按照“资源预留成本(Allocation)”、“资源使用成本(Usage)”和“集群开销(Overhead)”进行分类的一些常见示例。
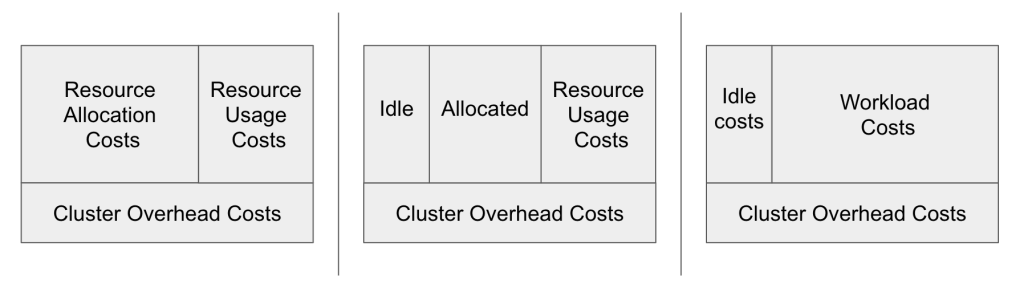
一旦算出了这些资产成本(Asset Costs),就可以把它们分摊给实际使用这些资源的租户。在这个分摊过程中:
- Workload Costs 指的是可以明确归属到某些 Kubernetes 工作负载(例如 container、pod、deployment 等)的那部分费用。
- Cluster Idle Costs 指的是资源已经被预留了(Allocation),但并没有被任何工作负载实际使用的那部分费用。
| Total Cluster Costs | = | Workload Costs | + | Cluster Idle Costs | + | Cluster Overhead Costs |
3. Cluster Asset Costs
Cluster Asset 是集群中可观察到的、会直接产生成本的实体。Asset 成本包含:
- Resource Allocation Costs
- Resource Usage Costs
每个 Asset 必须至少包含一个成本组件,包含:
- Amount(资源量)
- Unit(单位)
- Rate(价格)
- TotalCost(总成本)
3.1 Resource Allocation Costs(分配成本)属性
| 属性 | 含义 |
|---|---|
| Amount | 资源量,如 2 CPU cores |
| Duration | 分配时间(小时) |
| Unit | 资源单位,如 “CPU cores” |
| HourlyRate | 按单元每小时单价 |
| Total Cost | Amount × Duration × HourlyRate |
3.2 Resource Usage Costs(使用成本)属性
| 属性 | 含义 |
|---|---|
| Amount | 使用量,如 1GB egress |
| Unit | 单位 |
| UnitRate | 每单位价格 |
| TotalCost | Amount × UnitRate |
3.3 资产成本示例(按 24 小时计算)
1)Nodes(节点)
CPU 分配成本
- cores = avg_over_time(cpu) by node
- duration = 24 hrs
- price = provider 或自定义价格($/core-hr)
- total = cores × duration × price
RAM 分配成本
- ram bytes = avg_over_time(RAM)
- duration = 24 hrs
- price = $/GB-hr
- total = ram × duration × price
2)Persistent Volumes(持久卷)
- Disk Size = avg_over_time(GB)
- Price = 按磁盘类型、IOPS、备份成本决定
- total = size × price × duration
3)Attached Disks(挂载磁盘)
- Disk Size = avg_over_time(GB)
- Price = 按磁盘类型、IOPS、备份成本决定
- total = size × price × duration
4)Load Balancers(负载均衡器)
Usage(使用成本):
- amount = ingress bytes
- price = $/byte
Allocation(分配成本):
- rules = forwarding rules 数量
- price = 平均每条规则单价
3.4 Overhead Costs(集群管理开销)
包括:
- 集群管理费(按小时)
- 运维人员成本(可按比例分摊)
4. Workload Costs
💡 Workload 的成本 = 你占了多少资源,就按占的算;如果你用了更多,就按用的算。计算从 container 开始。
- Workload 就是要分摊成本的对象,比如 container、pod、deployment。
- 有些资源按 实际使用量 收费(比如网络流量)。
- 有些资源按 预留量(request) 收费(比如 CPU/GPU),不用也得付钱。
- 所以 Workload 成本 = max(request, usage)(预留和使用取大的那个)。
- 成本计算必须从 container 开始,因为它是资源使用的最小单位,之后可以按 pod、namespace 等随便汇总。
| 资源 | 度量方式 |
|---|---|
| CPU | max(使用量, request),单位 cores / mcores |
| Memory | max(使用量, request),单位 bytes |
| GPU | max(使用量, request),单位 GPU cores |
| PVC | PVC request 的容量 |
| Network | ingress/egress 字节数 |
| LB | LB 数量 + 请求量(视 provider 而定) |
一个完整实现应支持按以下维度进行聚合(支持的聚合维度):
- container
- pod
- deployment
- statefulset
- job
- controller name / kind
- label / annotation
- namespace
- cluster
5.Shared Costs(共享成本)
共享的工作负载成本、集群空闲成本以及集群管理开销成本,都是组织可以选择在租户之间进行分摊的成本类型。一个常见的例子是系统级工作负载的成本,例如 kube-system 中的 pods,这些资源会为所有租户带来收益。
常见的分摊方式包括:
- 在所有租户之间平均分配
- 按租户所消耗的集群资产成本的比例进行分配
- 使用自定义指标分配,例如按网络出口流量的字节数分配
一个完整实现的规范应该支持多种共享成本的分配方式。
6. Idle Costs(空闲成本)
空闲成本可以在资产/资源层面计算,也可以在工作负载层面计算。资产空闲成本表示集群资产成本与已经被分配或正在被消耗的资源成本之间按成本权重计算的差值。空闲成本和空闲百分比可以按照以下方式计算:
| Cluster Idle Cost | = | ( Cluster Asset Costs | – | Workload Costs ) |
| Cluster Idle % | = | Idle Cost | / | Resource Allocation Costs |
下面的图表展示了这些关系。
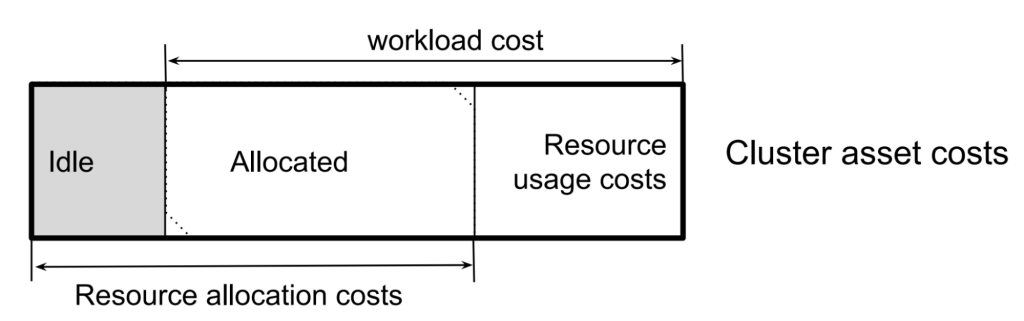
资产空闲成本可以针对单个资产、资产组、整个集群,或单独的资源(例如 CPU)进行计算。那些完全按照使用量计费的资源可以视为拥有 100% 的效率,但在计算集群空闲百分比时不应被纳入考虑。
工作负载空闲成本是一种基于成本权重来衡量“被请求但未被使用”的资源的方式。工作负载空闲成本可以针对任何 Kubernetes 工作负载的分组进行计算,例如容器、Pod、标签、注解、命名空间等。
7.Pod States(Pod 状态)
Pod 的状态会影响成本是否能被分配,以及某项资源是否被视为已分配。
OpenCost 模型不会将分配给处于 ImagePullBackOff 状态的 Pod 的资源计入成本。
| 状态 | 成本分配方式 | 状态说明 |
|---|---|---|
| Running | Max (Usage, request) | Implemented |
| ImagePullBackOff | Request | Currently no charge |
Appendix A(附录 A)
多个云服务提供商在其用户计费模型中,直接提供按小时计算的资源成本。当出现这种情况时,OpenCost 模型建议使用每种资源的 完全摊销净成本(fully Amortized Net Cost) 作为输入。
当云服务商没有明确提供 RAM、CPU 或 GPU 的单独价格时,OpenCost 模型需要推导这些数值。建议的方式是根据 CPU、GPU、RAM 以及其他价格输入之间的可扩展比例来计算。这些默认值应基于该云提供商不同实例家族中的边际资源成本。
一种计算方式是确保各组件的成本之和等于该资产(例如节点)的总价格,该价格依据提供商的计费标准。如果资源(例如 RAM/CPU/GPU)的成本之和大于(或小于)节点价格,则保持各输入单价之间的比例不变,但调整其总值,使其与节点总价一致。
例如,你配置了一台节点,其中包含 1 个 GPU、1 个 CPU 和 1GB 的 RAM,总成本为每月 35 美元。如果基于该实例家族的平均边际成本,你的基础价格为 GPU = $30、CPU = $30、RAM = $10,那么这些输入将被归一化为 GPU = $15、CPU = $15、RAM = $5,以使三者之和等于该节点的总成本。注意,GPU 和 CPU 的价格仍保持为 RAM 的 3 倍。
Appendix B(附录 B)
推荐使用以下指标/数据源对 Kubernetes 资源进行采样:
- container_cpu_usage_seconds_total – 由 cAdvisor 采样
- container_memory_working_set_bytes – 由 cAdvisor 采样
- gpu_usage – 通过芯片相关的特定指标采样
- cpu_requested – 来自 Kubernetes API
- ram_requested – 来自 Kubernetes API
- gpu_requested – 来自 Kubernetes API
