
1. 为什么 AI 算力平台一定会遇到多租户问题
在面向 AI 的 Kubernetes 集群中,多租户几乎是一个绕不开的话题。原因并不复杂:一套 GPU 集群成本高、资源稀缺,不可能长期按“每个团队一套独立集群”的方式无限扩张。
从资源利用率和运维复杂度的角度看,把多个团队、项目或租户承载到同一个共享集群中,几乎是必然选择。但共享集群并不意味着所有人都直接共用同一套资源。
在真实环境中,不同租户往往需要有各自独立的命名空间、权限边界、资源配额,甚至还会进一步要求专属节点、专属 GPU 资源和特定的调度约束。也就是说,AI 平台中的多租户问题,远不只是“把用户分到不同 Namespace”这么简单。
Kubernetes 原生提供了 Namespace 这一对象,用于把集群划分为逻辑上的隔离空间。但 Namespace 本身是扁平的,它更适合做基础隔离,而不是完整的租户抽象。一旦希望在多个 Namespace 之上再建立租户边界、继承策略和自主管理能力,原生 Namespace 模型就会很快触及边界。
很多组织在这里会走向另一种极端:干脆为每个团队单独分配一个独立集群。问题是,随着团队数量增长,这种方式会迅速演变成集群数量失控、配置难以统一、运维复杂度不断膨胀的典型 cluster sprawl。也正因为如此,共享集群之上的多租户治理,才会成为 AI 算力平台中的关键能力之一。
2. Capsule 的核心思路:在 Kubernetes 管理员与租户之间建立新边界
Capsule 提供的,并不是一套彻底改造 Kubernetes 使用方式的新平台,而是一种更轻量的多租户抽象。它的核心思路,是在原生 Kubernetes 能力之上,引入一个名为 Tenant 的概念,把多个 Namespace 聚合成一个逻辑租户,并围绕这个租户建立边界、策略和权限模型。
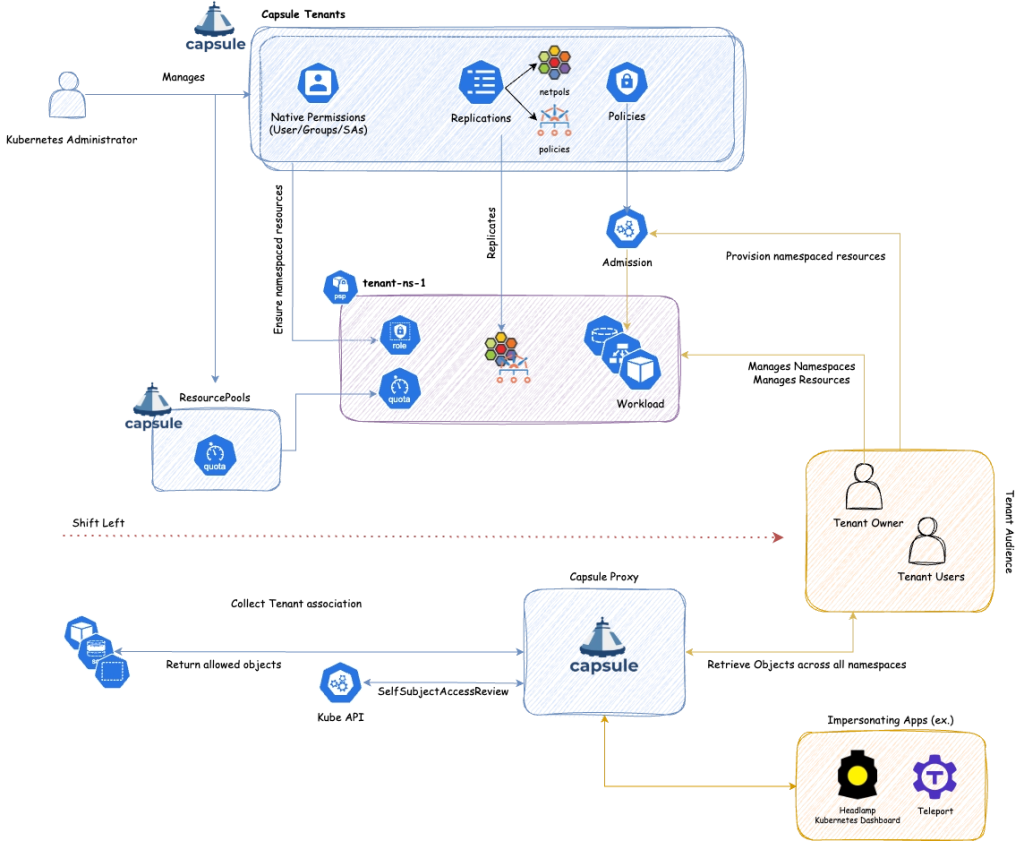
从角色上看,Capsule 在 Kubernetes 管理员与租户侧用户之间建立了一层新的分工:
- Kubernetes 管理员 负责定义租户边界;
- Tenant Owners 负责在租户内部创建和管理 Namespace;
- Tenant Users 则在所属租户的 Namespace 中开展日常操作。
这样做的一个直接好处是:原本必须由集群管理员完成的 Namespace 创建和管理动作,可以部分左移到 Tenant Owner 手中。租户获得了更高的自治能力,而集群管理员仍然保留对整体边界和治理规则的控制。
这也是 Capsule 在共享集群中最有价值的地方:它并不是让租户“拿到整个集群的权限”,而是在严格边界之内,把原本高度集中在管理员手里的部分能力,转化为租户内部的自主管理能力。
3. Capsule 解决什么问题,不解决什么问题
Capsule 解决的核心问题,是共享集群中的租户抽象与边界治理。它让多个 Namespace 不再只是彼此独立的扁平分区,而是可以被组织进同一个 Tenant 中,并继承统一的策略、配额、限制范围、RBAC 规则和安全边界。换句话说,Capsule 关注的是:如何在一个共享 Kubernetes 集群中,让多个租户既能共用底层平台,又能保持彼此隔离,并具备一定程度的自主管理能力。
但 Capsule 并不打算解决所有问题。例如,它并不负责 CRD 管理。如果你的平台中引入了大量 Operator 和自定义资源,如何对这些 CRD 做进一步约束和治理,仍然需要结合你自己的平台设计来处理。因此,Capsule 更适合作为“租户边界层”和“共享集群治理层”的组件,而不是把它理解成一套万能的多租户平台。
4. 为什么还需要 Capsule Proxy
在明确了 Capsule 的定位之后,接下来还需要回答一个更具体的问题:如果租户用户需要查看某些 cluster-scoped 资源,而原生 RBAC 又无法细粒度控制时,该怎么处理?这正是 Capsule Proxy 出现的背景。
在多租户场景下,一个很典型的问题是:租户用户往往需要查看自己拥有的某些 cluster-scoped 资源,但 Kubernetes 原生 RBAC 很难做到“只允许列出自己拥有的那一部分 cluster-scoped 资源”。例如,namespaces 本身就是 cluster-scoped 资源。如果不给 LIST 权限,用户会直接报错;但如果粗暴地给了 LIST 权限,用户又可能看到整个集群里的所有 Namespace。这在多租户环境中显然是不合适的。
很多 Kubernetes 发行版会选择引入镜像型自定义资源和 ACL 过滤 API 来解决这个问题。但这种做法往往会改变原生 Kubernetes 的使用体验,也会让平台的迁移与兼容性变差。
Capsule Proxy 的意义,就在于它尝试用另一种方式解决这个问题:在尽量保留原生 Kubernetes 使用体验的前提下,通过 Proxy 转发带 impersonation 的请求,让面向用户的工具仍然可以工作,同时又避免直接暴露不该暴露的 cluster-scoped 资源。对于希望尽量保持原生 Kubernetes 体验的平台来说,这是一个很重要的增强点。
5. Capsule 的部署与基础集成
在理解了 Capsule 和 Capsule Proxy 的角色之后,下一步就进入实际部署。这一部分的目标比较明确:先把 Capsule Controller 和 Capsule Proxy 安装到集群中,再补充必要的全局配置和角色权限定义,使集群具备最基础的多租户能力。
5.1 安装 Capsule Controller
真正创建 Tenant 之前,首先需要把 Capsule Controller 安装到集群中。它负责监听 Tenant CRD,并在租户边界、Namespace 归属和相关策略之间完成协调与校正。换句话说,Controller 是 Capsule 多租户能力真正生效的核心控制面组件。
这里通过 Helm 安装 Capsule Controller:
# 通过helm安装capsule
helm repo add projectcapsule <https://projectcapsule.github.io/charts>
helm repo update
helm pull projectcapsule/capsule --version 0.11.2
tar xf capsule-0.11.2.tgz
helm install capsule ./ -n capsule-system --create-namespace
安装完成后,先检查 Controller 是否已经正常运行:
# 检查
kubectl get pod -n capsule-system
NAME READY STATUS RESTARTS AGE
capsule-controller-manager-6dc88cc646-2kjh6 1/1 Running 1 (4m47s ago) 5m36s
5.2 安装 Capsule Proxy
仅安装 Capsule Controller 还不够。因为多租户环境下,租户用户访问 cluster-scoped 资源时的可见性问题仍然存在,因此这里继续安装 Capsule Proxy,用于解决租户侧访问 cluster-scoped 资源时的兼容与边界问题。
# 通过helm安装capsule-proxy
helm pull projectcapsule/capsule-proxy --version 0.9.13
tar xf capsule-proxy-0.9.13.tgz
helm install capsule-proxy ./ -n capsule-system
# 检查
kubectl get tenants
NAME STATE NAMESPACE QUOTA NAMESPACE COUNT NODE SELECTOR READY STATUS AGE
hypersuite Active 1 True reconciled 18d
5.3 检查部署结果
组件安装完成之后,还需要进一步确认 Deployment、Pod 和 CRD 都已正常就绪。 这一步的重点不是“命令有没有执行成功”,而是确认整个多租户基础层已经完整进入集群。
# 检查
kubectl get deployment -n capsule-system
NAME READY UP-TO-DATE AVAILABLE AGE
capsule-controller-manager 1/1 1 1 16m
capsule-proxy 1/1 1 1 64s
kubectl get pods -n capsule-system
NAME READY STATUS RESTARTS AGE
capsule-controller-manager-6dc88cc646-2kjh6 1/1 Running 1 (16m ago) 16m
capsule-proxy-66cc9cb445-49dlr 1/1 Running 0 106s
kubectl get crd | grep capsule
capsuleconfigurations.capsule.clastix.io 2025-12-30T09:13:27Z
globalproxysettings.capsule.clastix.io 2025-12-30T09:28:42Z
globaltenantresources.capsule.clastix.io 2025-12-30T09:13:27Z
proxysettings.capsule.clastix.io 2025-12-30T09:28:43Z
resourcepoolclaims.capsule.clastix.io 2025-12-30T09:13:27Z
resourcepools.capsule.clastix.io 2025-12-30T09:13:28Z
tenantresources.capsule.clastix.io 2025-12-30T09:13:28Z
tenants.capsule.clastix.io 2025-12-30T09:13:28Z
6. 专属节点:共享集群中的租户物理边界
在 AI 平台中,多租户往往不会停留在逻辑隔离层面,而会进一步走到物理资源边界。尤其是在 GPU 集群场景下,很多租户会要求:
- 专属 GPU 节点
- 避免与其他租户抢占同一批机器
- 系统组件仍然能够正常下发到这些节点
- 某些模型下载或运维任务只能落在特定节点上
这意味着,多租户治理不能只看 Tenant 和 Namespace,还必须进一步延伸到节点层。可以通过“租户专属污点 + PodNodeSelector + 系统组件放行”的方式,建立一套“共享集群下的专属节点模型”。
6.1 PodNodeSelector:把租户边界推进到节点调度层
如果只停留在 Namespace 和 Tenant 这一层,租户边界其实还不完整。因为对很多 AI 工作负载来说,真正关键的不只是“属于哪个租户”,而是“最终能被调度到哪些节点上”。尤其是在 GPU 集群中,一旦涉及专属节点、专属 GPU 资源、模型下载节点或特殊网络节点,租户边界就必须进一步延伸到调度层。从 Kubernetes 的原生能力来看,Pod 是否落到特定节点,通常依赖 nodeSelector、nodeAffinity、污点与容忍等机制。
但在多租户平台中,如果完全依赖租户自己在 YAML 中维护这些调度约束,本质上仍然是一种“约定式治理”:写对了,工作负载可以落到目标节点;写错了、漏写了,或者根本没有写,Pod 就可能进入不该进入的节点范围。
在普通业务集群中,这种问题也许只是调度偏差;但在 AI 算力平台里,它往往会直接影响 GPU 隔离、资源归属和租户边界。也正因为如此,这里启用了 PodNodeSelector admission plugin。
它的价值不只是“再增加一种调度能力”,而是把“Pod 能选择哪些节点”这件事,从租户侧 YAML 中零散维护的规则,提升为平台侧可控的准入逻辑。换句话说,平台不再只是建议租户“最好把 Pod 调度到这些节点”,而是可以在控制面上,把节点选择范围明确收敛到指定边界之内。
从专属节点策略的角度看,PodNodeSelector 与租户专属污点并不是替代关系,而是配套关系。
专属污点解决的是“别的 Pod 不要误入这批节点”,本质上是一种排他性的门禁;而 PodNodeSelector 解决的则是“本租户的 Pod 应该被限制在什么节点范围内”,本质上是一种调度边界控制。只有两者结合起来,专属节点策略才既具备隔离能力,也具备平台可控性。否则,平台即使已经给节点打上了租户专属污点,租户侧工作负载依然可能因为调度约束缺失而无法稳定落到自己的节点范围内,或者在规则不严谨时出现边界漂移。
另外,这一步之所以需要在所有 Master 节点上同步配置,是因为 PodNodeSelector 属于 API Server 侧的 admission 逻辑。在多 Master 架构中,任意一个 Pod 创建请求都有可能被路由到不同的控制平面节点处理。如果只有部分 Master 启用了该插件,而其他 Master 没有启用,那么相同类型的请求在不同 API Server 上可能会得到不同的准入结果:有的请求会按平台规则被限制节点范围,有的请求则可能直接按原始 YAML 通过。这种“有时生效、有时失效”的行为,在生产环境中比完全未配置更难排查,也会直接破坏多租户边界的一致性。
因此,这类 admission 相关配置必须在所有控制平面节点上保持一致,并在修改后逐一确认 API Server 已经正常重建并恢复服务。在实际操作上,这里是在所有 Master 节点的 /etc/kubernetes/manifests/kube-apiserver.yaml 中,为 API Server 增加 PodNodeSelector admission plugin。由于 kube-apiserver 以静态 Pod 方式运行,修改清单文件后,Kubernetes 会自动重建对应 Pod。因此,完成配置后还需要进一步检查三台 Master 上的 API Server Pod 是否都已恢复到正常运行状态,以确认控制平面已经重新进入稳定状态。
# 所有master节点编辑添加PodNodeSelector
sudo vi /etc/kubernetes/manifests/kube-apiserver.yaml
creationTimestamp: null
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=10.x.x.x
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --enable-admission-plugins=NodeRestriction,PodNodeSelector
# 确认是否自动重启
kubectl get pods -n kube-system| grep api
kube-apiserver-master-01 1/1 Running 0 18d
kube-apiserver-master-02 1/1 Running 0 18d
kube-apiserver-master-03 1/1 Running 0 18d
6.2 专属节点上的系统 DaemonSet 放行
在专属节点策略建立起来之后,租户边界在节点层已经初步成形。但这时会很快遇到一个非常现实的问题:节点虽然已经通过 tenant-dedicated=<tenant>:NoSchedule 这样的污点完成了租户隔离,但很多系统级 DaemonSet 也会因此被一并挡在外面。
这意味着,专属节点虽然“属于某个租户”,但并不一定已经具备完整的平台运行能力。如果这一层不处理,后果往往不是租户工作负载无法启动这么简单,而是更底层的系统能力根本下不去。例如:
- GPU 设备发现组件可能无法进入节点;
- 节点标签同步组件可能无法正常运行;
- 监控采集或网络相关组件也可能出现缺失;
- 最终导致这批节点虽然被划给了某个租户,但实际上并没有被完整纳管。
对于 AI 算力平台来说,这个问题尤其重要。因为 GPU 节点并不是“普通的可调度机器”,它们往往需要额外依赖设备插件、标签同步、监控采集以及部分网络组件,才能真正成为可用于训练和推理的计算节点。如果专属节点策略只做了隔离,而没有继续处理这些系统级组件的放行,那么平台得到的将不是“专属节点”,而只是“一批被隔离但能力不完整的机器”。
也正因为如此,在租户专属节点模型中,必须额外考虑一个平衡:一方面,要继续保持专属节点对普通工作负载的排他性;另一方面,又要允许那些真正属于“平台基础能力”的系统组件继续进入这些节点。换句话说,这一步的目标,并不是削弱租户隔离,而是在不破坏边界的前提下,让节点仍然保持完整的平台能力。
# 1. 查看专属节点
# 在处理系统级 DaemonSet 放行之前,首先需要明确当前集群中到底有哪些节点已经被设置为租户专属节点。
kubectl get nodes -o json | jq -r '
.items[]
| select(.spec.taints != null)
| select(any(.spec.taints[]; .key == "tenant-dedicated"))
| .metadata.name as $n
| .spec.taints[]
| select(.key == "tenant-dedicated")
| "\\($n)\\ttenant-dedicated=\\(.value // ""):\\(.effect)"
' | sort
gpu-worker-100 tenant-dedicated=tenant01:NoSchedule
gpu-worker-25 tenant-dedicated=tenant01:NoSchedule
gpu-worker-26 tenant-dedicated=tenant01:NoSchedule
gpu-worker-27 tenant-dedicated=tenant01:NoSchedule
gpu-worker-28 tenant-dedicated=tenant01:NoSchedule
# 这一步的意义并不只是列清单,而是为了给后续验证建立边界:只有先明确哪些节点已经进入专属模式,后面的 DaemonSet 检查和放行结果才有参照对象。
# 2. 确认DS的数量是否正确
# 检查哪些 DaemonSet 受到了影响
# 明确专属节点范围之后,下一步就需要查看当前集群中哪些系统级 DaemonSet 可能受到了租户专属污点的影响。
kubectl get ds -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
dev-ips-server csi-nfs-node 102 102 100 102 100 kubernetes.io/os=linux 148d
kube-flannel kube-flannel-ds 102 102 100 102 100 <none> 149d
kube-system kube-multus-ds 102 102 97 100 97 <none> 114d
kube-system kube-proxy 102 102 100 102 100 kubernetes.io/os=linux 149d
kube-system rdma-shared-dp-ds 97 97 97 97 97 <none> 99d
kube-system whereabouts-whereabouts-chart 102 102 97 102 97 kubernetes.io/os=linux 93d
mars-operator mars-gpu-device 74 74 74 74 74 mars-tech.com/gpu.installed=true 16d
mars-operator mars-gpu-label 75 75 74 75 74 <none> 16d
metallb-system metallb-speaker 97 97 94 97 94 kubernetes.io/os=linux 98d
monitoring mars-ht-exporter 97 97 93 96 93 <none> 60d
monitoring prometheus-stack-prometheus-node-exporter 102 102 97 98 97 kubernetes.io/os=linux 60d
node-feature-discovery nfd-node-feature-discovery-worker 97 97 94 96 94 <none> 99d
在 AI 算力平台中,最值得重点关注的往往不是所有 DaemonSet,而是那些直接关系到 GPU 节点纳管和资源暴露的组件。例如:
mars-gpu-device
这类组件如果无法进入专属节点,那么这些节点即使物理上具备 GPU,也可能无法在 Kubernetes 视角中表现为完整可用的算力节点。举例来说mars-gpu-device 的作用,是在节点上发现 GPU 设备并将相关资源暴露给集群。
如果这个组件无法进入某批专属节点,那么这些节点即使物理上装有 GPU,也可能无法在 Kubernetes 视角中表现为可用算力。换句话说,租户虽然“拿到了节点”,但平台并没有真正把这批节点纳管成可调度 GPU 节点。因此,这里首先为 mars-gpu-device 增加 tenant-dedicated 污点的 toleration。
# 修正所有被污点影响的DS
1.mars-gpu-device
kubectl patch ds mars-gpu-device -n mars-operator --type='json' \\
-p='[
{
"op":"add",
"path":"/spec/template/spec/tolerations",
"value":[
{
"key":"tenant-dedicated",
"operator":"Exists",
"effect":"NoSchedule"
}
]
}
]'
这里采用的是为 DaemonSet 模板直接追加 toleration 的方式,使后续该组件创建出的所有 Pod 都能够容忍 tenant-dedicated:NoSchedule 污点,从而继续下发到租户专属节点。
kubectl get pods -n mars-operator -o wide | grep mars-gpu-device | egrep 'gpu-worker-55|gpu-worker-56|gpu-worker-57|gpu-worker-58'
mars-gpu-device-2fwgs 1/1 Running 0 44s 192.168.99.175 gpu-worker-57 <none> <none>
mars-gpu-device-ncjw4 1/1 Running 0 44s 192.168.95.143 gpu-worker-55 <none> <none>
mars-gpu-device-rv7bg 1/1 Running 0 44s 192.168.97.87 gpu-worker-58 <none> <none>
mars-gpu-device-xzknm 1/1 Running 0 44s 192.168.98.107 gpu-worker-56 <none> <none>
从 Kubernetes 原生能力来看,Namespace 提供的是基础隔离,但并不足以支撑 AI 算力平台中的完整多租户治理。一旦进入 GPU 集群、共享节点、专属资源和平台组件协同这一层,多租户边界就必须进一步延伸到租户抽象、控制面准入和节点调度层。
Capsule 的价值,正在于它为共享集群提供了 Tenant 这一层更适合平台治理的抽象;而在 AI 场景中,真正的多租户落地又不能停留在 Tenant 和 Namespace 本身,还必须继续走到专属节点、PodNodeSelector、租户专属污点以及系统级 DaemonSet 放行这些更底层的实现细节。
也就是说,AI 算力平台中的多租户,从来都不是单一组件的问题。它既是控制面的边界治理问题,也是节点层和资源层的协同问题。只有把这几层同时打通,共享集群中的租户隔离才会真正具备可落地性。


