在前一章节中,重点讨论的是 Kubernetes 作为容器化平台,如何为 AI 算力提供统一的运行与调度底座。但对于生产环境来说,仅仅把容器平台搭起来还远远不够。平台能够稳定承载工作负载,只是第一步;要让整套系统真正具备持续交付和规模化运行能力,还需要解决镜像从哪里来、如何统一管理、以及如何稳定分发到各节点的问题。
也正因为如此,镜像仓库就成为生产级 AI 平台中不可缺少的一环。如果说 Kubernetes 提供的是算力运行的承载空间,那么镜像仓库解决的,就是这套平台的软件供应与镜像分发问题。
1. Harbor 安装与基础配置
对于实验环境来说,一个最简的 Docker Registry 往往已经能够满足基本的镜像上传与拉取需求。但在生产环境中,镜像仓库通常不只是“能存镜像”就够了,还需要同时具备项目管理、权限控制、镜像检索、漏洞扫描以及 Web UI 等能力。也正因为如此,这里不选择最简 Registry,而是直接采用功能更完整、实际生产环境中更常见的 Harbor。
这一部分的目标比较明确:先把 Harbor 安装起来,并完成几个核心参数的基础配置,使其能够作为一个可访问、可管理的私有镜像仓库稳定运行。后续客户端接入、镜像导入导出、containerd mirror 配置以及 Trivy 扫描能力,都会建立在这一阶段完成的基础之上。
1.1 获取 Harbor 安装包
Harbor 官方同时提供在线安装包和离线安装包。从部署便利性来看,在线安装包更轻量;但在很多生产环境中,尤其是内网、半离线或需要严格控制外部依赖的场景下,离线安装包通常更合适。因为它能尽量减少安装时对外部网络的依赖,也更便于后续归档和复用。因此,这里优先采用离线安装包进行说明。
**如果没有特别需要,生产环境更推荐优先使用离线安装包。**解压完成后,进入 Harbor 目录,并从模板复制出实际使用的 harbor.yml 配置文件。这一动作的意义在于:Harbor 安装并不是“下载完直接执行 install.sh”,而是必须先根据当前环境调整访问地址、端口和数据目录等关键参数。
# 下载harbor离线安装包
wget <https://github.com/goharbor/harbor/releases/download/v2.14.0/harbor-offline-installer-v2.14.0.tgz>
tar xzvf harbor-offline-installer-v2.14.0.tgz
# (可选)
# 下载harbor在线安装包
wget <https://github.com/goharbor/harbor/releases/download/v2.14.0/harbor-online-installer-v2.14.0.tgz>
tar xzvf harbor-online-installer-v2.14.0.tgz
cd harbor
cp harbor.yml.tmpl harbor.yml
1.2 修改 Harbor 核心配置
Harbor 的安装脚本本身并不复杂,真正需要认真处理的是安装前的配置文件。对于第一次部署来说,不需要一次性修改所有参数,最重要的是先把几个直接影响访问方式和数据落盘位置的关键项处理正确。
# 修改harbor.yaml
vi harbor.yml
**# 1.修改hostname
# 2.修改port
# 3.如果是非生产环境建可以关闭https
# 4.修改提供给harbor的存储挂载路径**
# Configuration file of Harbor
# The IP address or hostname to access admin UI and registry service.
# DO NOT use localhost or 127.0.0.1, because Harbor needs to be accessed by external clients.
hostname: 10.x.x.x
# http related config
http:
# port for http, default is 80. If https enabled, this port will redirect to https port
port: 30002
# https related config
#https:
# https port for harbor, default is 443
# port: 443
# The path of cert and key files for nginx
# certificate: /your/certificate/path
# private_key: /your/private/key/path
# enable strong ssl ciphers (default: false)
# strong_ssl_ciphers: false
# The default data volume
data_volume: /data/nvme1/harbor-data
hostname
它决定了 Harbor 对外提供服务的地址。这个值不能写成 localhost 或 127.0.0.1,因为 Harbor 最终需要被其他客户端访问,包括 Docker 主机、containerd 节点和后续 Kubernetes 集群中的工作负载。因此,这里通常应填写实际可访问的 IP 地址或域名。
http.port
它定义 Harbor 对外监听的 HTTP 端口。如果当前环境还没有准备 HTTPS 证书,或者只是内网验证环境,那么通过自定义 HTTP 端口快速完成部署是很常见的做法。
https
在正式生产环境中,Harbor 通常仍然建议启用 HTTPS。因为一旦涉及认证信息传输、跨节点镜像拉取和多团队共享使用,明文 HTTP 的方式在安全性上会受到明显限制。不过,在早期实验环境、临时验证环境或纯内网封闭测试环境中,临时关闭 HTTPS 也是可以接受的,前提是你自己清楚这是一个“为了简化部署而做的阶段性妥协”,而不是长期推荐状态。
data_volume
这个参数决定 Harbor 数据落盘路径,包括镜像数据、数据库、Job 日志、扫描缓存等关键内容。因此,它不应该随意放在系统盘的默认位置,而应尽量选择容量和性能都更合适的存储路径。这里把数据目录指向 /data/nvme1/harbor-data,本质上就是在为后续镜像仓库的数据增长预留更合理的承载空间。
1.3 执行 Harbor 安装验证
在配置文件修改完成之后,就可以正式开始安装 Harbor。这里选择在安装时同时启用 Trivy.
Harbor 安装脚本执行完成后,建议不要急着先打开 Web 页面,而是先从容器层面确认服务是否都已经拉起。因此,第一步通常是检查 docker ps,确认 Harbor 相关组件是否已经进入运行状态。只有当这些核心容器都已经正常启动,后续的访问验证才有意义。如果后续需要停止 Harbor 或重新启动服务,也可以通过 docker compose down -v 和 docker compose up -d 进行管理。
# 安装部署
sudo ./install.sh --with-trivy
# 检查
docker ps
# 常用命令
sudo docker compose down -v
sudo docker compose up -d
# 缺省用户名密码
admin Harbor12345
到这里,Harbor 已经完成基础安装,并具备了作为私有镜像仓库提供服务的基本能力。从平台视角看,这意味着镜像补给站已经初步搭建完成:后续无论是 Docker 客户端、containerd 节点,还是 Kubernetes 集群中的各类组件和业务镜像,都可以围绕这个统一的仓库入口进行归集和分发。不过,此时 Harbor 还只是“服务已经起来了”,并不代表它已经真正融入整个平台。
2.客户端接入:让 Harbor 真正进入节点侧
到这里,Harbor 本身已经完成安装,并具备了最基本的服务能力。但对于生产环境来说,仓库服务“已经启动”只是第一步,更关键的是让实际使用镜像的客户端能够顺利接入。否则,Harbor 即使已经部署完成,也仍然只是一个“摆在那里”的仓库,而无法真正进入平台镜像分发链路。
在实际环境中,客户端的接入方式通常取决于底层容器运行时。如果节点主要通过 Docker 管理镜像,那么需要在 Docker 客户端侧完成仓库访问方式配置;如果节点底层使用的是 containerd,那么还需要进一步修改 containerd 的镜像源配置,使其能够把 Harbor 识别为可访问的私有镜像仓库。也正因为如此,这一部分不再关注 Harbor 服务端本身,而是分别从 Docker 和 containerd 两个方向出发,说明节点侧如何真正接入这个私有镜像仓库。
2.1 Docker 客户端接入 Harbor
在 Docker 场景下,客户端接入 Harbor 的关键点,通常不在于“如何登录”,而在于当前 Docker 守护进程是否允许以预期方式访问目标仓库。如果 Harbor 使用的是 HTTP 服务,或者使用的是自签名证书,那么客户端往往需要显式调整 daemon.json 中的访问策略,否则即使仓库地址正确,也可能在实际登录或拉取镜像时失败。
因此,这一步的重点,是先在 Docker 客户端上明确私有仓库的访问方式,再通过 docker login 验证客户端与 Harbor 之间的连通性和认证是否正常。这里可以在 Ubuntu 系统中通过修改 /etc/docker/daemon.json 的方式,为 Docker 增加 insecure-registries 配置,并按需保留国内公共镜像加速源。
配置完成后,需要重启 Docker 服务,并通过 docker info 确认配置已经被正确加载。在此基础上,再执行 docker login,验证 Harbor 仓库是否可以正常完成认证。你现有的 Docker 客户端配置命令,可以直接放在这里。
**# uBuntu系统 docker方式**
sudo mkdir -p /etc/docker
cat << 'EOF' | sudo tee /etc/docker/daemon.json
{
"registry-mirrors": [
"<https://registry.docker-cn.com>",
"<https://mirror.baidubce.com>",
"<https://hub-mirror.c.163.com>"
],
"insecure-registries": [
"10.x.x.100:60066",
"10.xx.xx.x:60066"
],
"debug": true,
"experimental": false
}
EOF
systemctl restart docker
# 确认更改成功
docker info | grep -i "Insecure Registries" -A10
# 登陆私有仓库
docker login 10.x.x.x:30002
2.2 containerd 节点接入 Harbor
相比 Docker,containerd 的接入方式更偏底层,也更贴近 Kubernetes 节点的真实运行环境。
对于 AI 平台来说,这一点尤其重要,因为很多 Worker Node 上真正负责镜像拉取与运行的,并不是 Docker,而是 Kubernetes 所依赖的 containerd。在这种场景下,仅仅让 Harbor “能登录”是不够的,还需要让 containerd 在拉取镜像时,能够把目标地址识别为合法的镜像源,并根据当前环境正确处理 HTTP、HTTPS 或 mirror 配置。也就是说,这一步解决的问题不是“人能访问 Harbor”,而是“节点本身能否把 Harbor 当作镜像源来使用”。
最直接的方式,是在 config.toml 中追加对应的 registry.mirrors 配置,并在修改后重启 containerd,使配置真正生效。配置完成后,除了检查配置文件内容之外,也建议同步检查 containerd 服务状态,以避免出现“文件已改但服务未重载”的情况。
**# uBuntu系统 containerd方式**
ll /etc/containerd/
sudo sed -i '/\\[plugins."io.containerd.grpc.v1.cri".registry\\]/a [plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.x.x.x:60066"]\\n endpoint = ["<http://10.x.x.x:60066>"]' /etc/containerd/config.toml
# 重启服务
sudo systemctl restart containerd
# 检查是否写入文件
grep -A3 'registry.mirrors."10.80.17.128:60066"' /etc/containerd/config.toml
3.镜像流转:从离线导入到统一上传
当 Harbor 已经可以被客户端正常访问之后,下一步就进入更具体的镜像流转阶段。对于 AI 平台而言,这一步并不只是简单的 push 或 pull,而往往涉及离线镜像加载、镜像重打标签、批量上传、节点侧批量加载以及跨仓库迁移等多种操作方式。
这类场景在生产环境中很常见。有些镜像来源于公网,需要先下载后导入内网仓库;有些镜像已经存在于其他私有仓库,需要重新标记并迁移到新的 Harbor 项目中;还有一些镜像则需要提前分发到大量 Worker Node,以适应离线环境或高并发部署场景。因此,这里不会把镜像处理理解为单条命令,而是把它看作一条完整的镜像交付链路。
3.1 Docker 方式的镜像导入与上传
在 Docker 使用场景下,镜像流转通常遵循一个最常见的路径:先把镜像从离线包导入到本地 Docker,再重新打上 Harbor 仓库地址对应的 tag,最后推送到私有仓库中。
如果需要把一组镜像统一导出到离线环境,也可以通过 docker save 一次性打包多个镜像。这种方式的优点是直观,适合人工验证,也适合中小规模镜像处理。
# 离线镜像加载
docker load -i xxx.tar/xxx.xz
# 镜像打标
docker tag longhornio/longhorn-manager:v1.10.1 10.x.x.x:30002/longhorn/longhorn-manager:v1.10.1
# 镜像上传至私有仓库
docker push 10.x.x.x:30002/longhorn/longhorn-manager:v1.10.1
# 批量打包
docker save -o csi-all-v2.10.0.tar \\
10.60.17.100:60066/csi/ibm-spectrum-scale-csi-driver:v2.10.0 \\
10.60.17.100:60066/csi/ibm-spectrum-scale-csi-operator:v2.10.0 \\
10.60.17.100:60066/csi/livenessprobe:v2.10.0 \\
10.60.17.100:60066/csi/csi-snapshotter:v2.10.0 \\
10.60.17.100:60066/csi/csi-resizer:v2.10.0 \\
10.60.17.100:60066/csi/csi-provisioner:v2.10.0 \\
10.60.17.100:60066/csi/csi-node-driver-registrar:v2.10.0 \\
10.60.17.100:60066/csi/csi-attacher:v2.10.0
3.2 containerd 方式的镜像导入与上传
如果节点底层使用的是 containerd,那么镜像导入和上传流程与 Docker 会有明显区别。这里不仅命令不同,连镜像所在的命名空间、认证方式以及是否使用 plain-http 等参数,也都需要额外注意。例如,在 Kubernetes 节点上,常见的镜像操作通常会落在 k8s.io 命名空间下;
如果忽略这一点,可能会出现镜像“已经导入但 Kubernetes 看不到”的情况。另外,在向私有仓库推送镜像时,还要考虑当前 Harbor 是否启用了 HTTPS、是否需要显式传入用户名密码、以及是否需要指定平台架构等因素。也就是说,containerd 场景中的镜像流转,已经不只是“导入和推送”本身,而是更接近 Kubernetes 节点侧的真实镜像管理过程。对 AI 平台来说,这部分尤其值得重视,因为很多训练、推理工作负载最终都是直接运行在 containerd 之上的。
# 镜像导出
sudo ctr -n k8s.io image export vllm:hpcc.ai3.1.0.7-torch2.6-py310-ubuntu22.04-amd64-20251223.tar x.x.x.x:8091/mars/vllm:hpcc.ai3.1.0.7-torch2.6-py310-ubuntu22.04-amd64-20251223
# 离线镜像加载
ctr -n k8s.io images import ./image_localpv-provisioner-4.0.0-20260106031906-67da939.tar
# 镜像打标
ctr -n k8s.io images tag cr.io.plus:80/ioview/dynamic-localpv-provisioner:20260106031906-67da939 x.x.x.x:8091/posix-csi/dynamic-localpv-provisioner:20260106031906-67da939
# 镜像上传至私有仓库
ctr -n k8s.io images push --plain-http --user 'admin:xxx --platform linux/amd64 112.65.216.101:8091/posix-csi/dynamic-localpv-provisioner:20260106031906-67da939
# 检查
ctr -n k8s.io images ls | egrep -i 'localpv|provisioner|image_localpv' || true
3.3 用 skopeo 快速完成跨仓库对拷
如果目标不是先把镜像拉到本地,再重新打包、重打 tag、再推送到目标仓库,而是希望直接在源仓库和目标仓库之间完成复制,那么 skopeo copy 会是一种更直接、更高效的方式。相比传统的 docker pull + docker tag + docker push,skopeo copy 少了中间本地落盘和重新导入的步骤,因此特别适合做仓库之间的镜像迁移、镜像归档整理或者批量搬运。对于生产环境来说,这种方式能够显著降低中间链路的复杂度,也更适合做脚本化处理。
# 这个可以替代麻烦的docker打标
skopeo copy \\
docker://ghcr.io/kubeflow/model-registry/ui:v0.2.19 \\
docker://10.x.x.x:60066/kubeflow/ghcr.io/kubeflow/model-registry/ui:v0.2.19 \\
--src-tls-verify=true \\
--dest-tls-verify=false \\
--dest-creds=admin:xxxx
4.Trivy:从镜像存储到镜像安全扫描
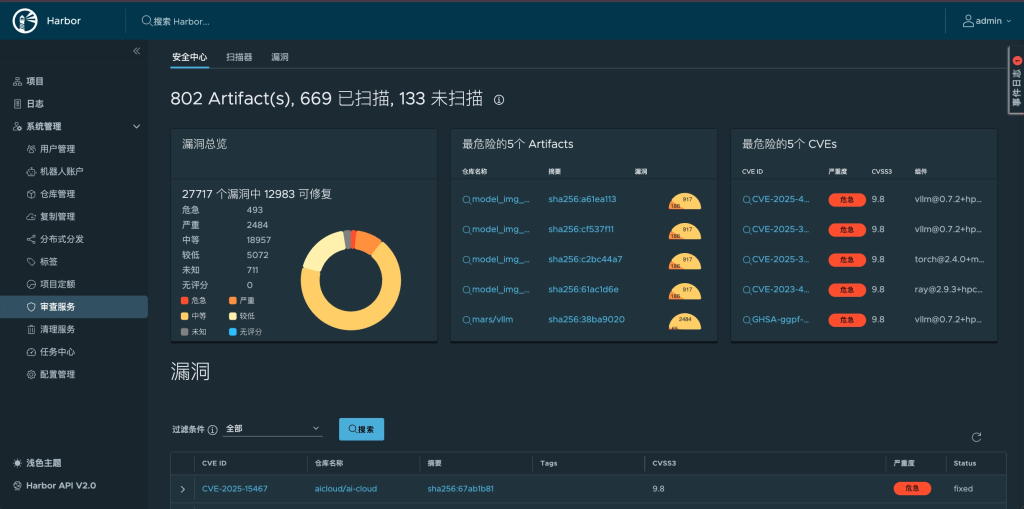
对生产环境而言,一个可用的镜像仓库并不只是负责存储和分发镜像,还应该具备基本的安全治理能力。Harbor 集成 Trivy 的意义,正是在于为镜像仓库补上漏洞扫描这一层,使镜像管理从“能存、能拉、能推”进一步走向“可检查、可审视、可治理”。
对于 AI 平台来说,这一点并不只是安全部门的附加要求。很多训练镜像、推理镜像和基础环境镜像体积大、依赖复杂,往往同时包含 Python 包、系统库和 AI 框架组件。
这也意味着它们在漏洞暴露面上通常比普通业务镜像更复杂。如果镜像仓库完全缺少扫描和可视化审视能力,那么平台在后续交付和运维阶段会明显缺少一层治理抓手。也正因为如此,这里继续补充 Harbor 中 Trivy 扫描能力的启用方式,以及在离线环境下如何处理漏洞数据库同步问题。
4.1 启用 Trivy 扫描能力
Harbor 在安装时已经支持通过参数启用 Trivy。如果初始安装阶段没有启用,也可以在后续通过 prepare --with-trivy 的方式重新生成配置,并启动 trivy-adapter 容器。这一步解决的问题,不是“让 Harbor 看起来更完整”,而是让镜像仓库真正具备基础扫描能力。只有扫描链路跑起来之后,Harbor 中的镜像管理才开始具备安全维度的可见性。
# 进入Harbor安装目录
cd /data/nvme0/hh/harbor
# 增加trivy功能
sudo ./prepare --with-trivy
# 启动Trivy-adpater
sudo docker down
sudo docker compose up -d
或
sudo docker compose up -d trivy-adapter
4.2 在线拉取失败分析
在实际部署中,Trivy 默认需要从外部镜像源下载漏洞数据库。如果当前环境无法访问 mirror.gcr.io 或相关外部地址,就会导致数据库下载失败,从而进一步造成扫描任务失败。
这个问题在内网环境、半离线环境或受限网络环境中非常常见。表面上看是 Harbor 扫描失败,实际上根因并不在 Harbor 本体,而在于 Trivy 无法完成漏洞数据库同步。例如当前日志里已经把问题暴露得很清楚了:Trivy 在执行扫描时尝试访问 mirror.gcr.io/aquasec/trivy-db:2,但由于当前网络无法连通,最终导致 DB 下载失败,进而使整个扫描任务报错。
sudo docker logs --since 30m trivy-adapter | tail -n 200
{"time":"2026-01-29T11:59:03.583515581Z","level":"ERROR","msg":"Running trivy failed","image_ref":"core:8080/aicloud/ai-cloud@sha256:797c4d25a509402ae498f0a84d73a57591d852fcbb61f586b89c186802f522ec","exit_code":"1","std_out":"2026-01-29T11:45:57Z\\tWARN\\t'--vuln-type' is deprecated. Use '--pkg-types' instead.\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Need to update DB\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading vulnerability DB...\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading artifact...\\trepo=\\"mirror.gcr.io/aquasec/trivy-db:2\\"\\n2026-01-29T11:59:03Z\\tFATAL\\tFatal error\\trun error: init error: DB error: failed to download vulnerability DB: OCI artifact error: failed to download vulnerability DB: failed to download artifact from mirror.gcr.io/aquasec/trivy-db:2: OCI repository error: 2 errors occurred:\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\n\\n"}
{"time":"2026-01-29T11:59:03.583747667Z","level":"ERROR","msg":"Scan failed","err":"running trivy wrapper: running trivy: exit status 1: 2026-01-29T11:45:57Z\\tWARN\\t'--vuln-type' is deprecated. Use '--pkg-types' instead.\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Need to update DB\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading vulnerability DB...\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading artifact...\\trepo=\\"mirror.gcr.io/aquasec/trivy-db:2\\"\\n2026-01-29T11:59:03Z\\tFATAL\\tFatal error\\trun error: init error: DB error: failed to download vulnerability DB: OCI artifact error: failed to download vulnerability DB: failed to download artifact from mirror.gcr.io/aquasec/trivy-db:2: OCI repository error: 2 errors occurred:\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\n\\n"}
{"time":"2026-01-29T11:59:06.412874233Z","level":"ERROR","msg":"Scan job failed","scan_job_id":"14d3dc8542749024f8db7332","mime_type":"application/vnd.security.vulnerability.report; version=1.1","scan_job_status":"Failed","err":"running trivy wrapper: running trivy: exit status 1: 2026-01-29T11:45:57Z\\tWARN\\t'--vuln-type' is deprecated. Use '--pkg-types' instead.\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Need to update DB\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading vulnerability DB...\\n2026-01-29T11:45:57Z\\tINFO\\t[vulndb] Downloading artifact...\\trepo=\\"mirror.gcr.io/aquasec/trivy-db:2\\"\\n2026-01-29T11:59:03Z\\tFATAL\\tFatal error\\trun error: init error: DB error: failed to download vulnerability DB: OCI artifact error: failed to download vulnerability DB: failed to download artifact from mirror.gcr.io/aquasec/trivy-db:2: OCI repository error: 2 errors occurred:\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\n\\n"}
{"time":"2026-01-29T12:12:10.006360117Z","level":"ERROR","msg":"Running trivy failed","image_ref":"core:8080/aicloud/ai-cloud@sha256:d09aaa80a03158ef2803ceb70a53bbd7963131e49d40859b2f816dec3af6d4b8","exit_code":"1","std_out":"2026-01-29T11:59:03Z\\tWARN\\t'--vuln-type' is deprecated. Use '--pkg-types' instead.\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Need to update DB\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Downloading vulnerability DB...\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Downloading artifact...\\trepo=\\"mirror.gcr.io/aquasec/trivy-db:2\\"\\n2026-01-29T12:12:09Z\\tFATAL\\tFatal error\\trun error: init error: DB error: failed to download vulnerability DB: OCI artifact error: failed to download vulnerability DB: failed to download artifact from mirror.gcr.io/aquasec/trivy-db:2: OCI repository error: 2 errors occurred:\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\n\\n"}
{"time":"2026-01-29T12:12:10.006546008Z","level":"ERROR","msg":"Scan failed","err":"running trivy wrapper: running trivy: exit status 1: 2026-01-29T11:59:03Z\\tWARN\\t'--vuln-type' is deprecated. Use '--pkg-types' instead.\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Need to update DB\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Downloading vulnerability DB...\\n2026-01-29T11:59:03Z\\tINFO\\t[vulndb] Downloading artifact...\\trepo=\\"mirror.gcr.io/aquasec/trivy-db:2\\"\\n2026-01-29T12:12:09Z\\tFATAL\\tFatal error\\trun error: init error: DB error: failed to download vulnerability DB: OCI artifact error: failed to download vulnerability DB: failed to download artifact from mirror.gcr.io/aquasec/trivy-db:2: OCI repository error: 2 errors occurred:\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\t* Get \\"<https://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:443: connect: connection timed out; Get \\"<http://mirror.gcr.io/v2/\\>": dial tcp 142.250.107.82:80: connect: connection timed out\\n\\n\\n"}
4.3 部署离线CVE DB
既然在线拉取失败,最直接的解决思路就是改为离线导入漏洞数据库。这也是很多内网生产环境更常见的做法:先在具备外网访问能力的环境中下载 Trivy DB,再把数据库文件导入 Harbor 所使用的 Trivy 缓存目录,并通过环境变量显式切换到离线扫描模式。
这一步通常包括几个核心动作:
- 使用
oras拉取trivy-db制品; - 解压数据库文件;
- 将
trivy.db和metadata.json放到 Harbor 对应的 Trivy 数据目录中; - 修正文件权限,确保容器内用户可正常读取;
- 修改 Trivy adapter 的环境变量,关闭在线更新并启用离线扫描;
- 重启相关服务,使新配置生效。
这部分的价值,不只是“把扫描修好”,而是让 Harbor 在完全离线或受限网络环境中,依然具备漏洞扫描能力。对于很多企业内网环境而言,这是镜像安全治理真正能落地的关键一步。
snap install oras --classic
# 下载db文件
oras pull ghcr.io/aquasecurity/trivy-db:2
root@homelab:~/charts# ll
total 840412
drwxr-xr-x 8 root root 4096 Jan 29 12:34 ./
drwx------ 18 root root 4096 Jan 29 09:35 ../
-rw-r--r-- 1 root root 87635718 Jan 29 12:36 db.tar.gz
# 解压DB文件
tar -zxvf db.tar.gz
# 创建 db 子目录(如果不存在)
mkdir -p /data/nvme1/harbor-data/trivy-adapter/trivy/db/
# 拷贝解压出的文件
cp trivy.db metadata.json /data/nvme1/harbor-data/trivy-adapter/trivy/db/
# 重要:修正权限(Trivy 容器内用户 ID 通常是 10000 或 1000)
chown -R 10000:10000 /data/nvme1/harbor-data/trivy-adapter/trivy/db/
chmod -R 755 /data/nvme1/harbor-data/trivy-adapter/trivy/db/
# 编辑换进变量
cd harbor/common/config/trivy-adapter
vi env
# 找到并修改这几项
SCANNER_TRIVY_SKIP_UPDATE=True # 设为 True,跳过在线更新
SCANNER_TRIVY_OFFLINE_SCAN=True # 设为 True,完全离线模式
SCANNER_TRIVY_SKIP_JAVA_DB_UPDATE=True # 同样跳过 Java 库
docker-compose down
docker-compose up -d
4.4 在界面中验证扫描结果
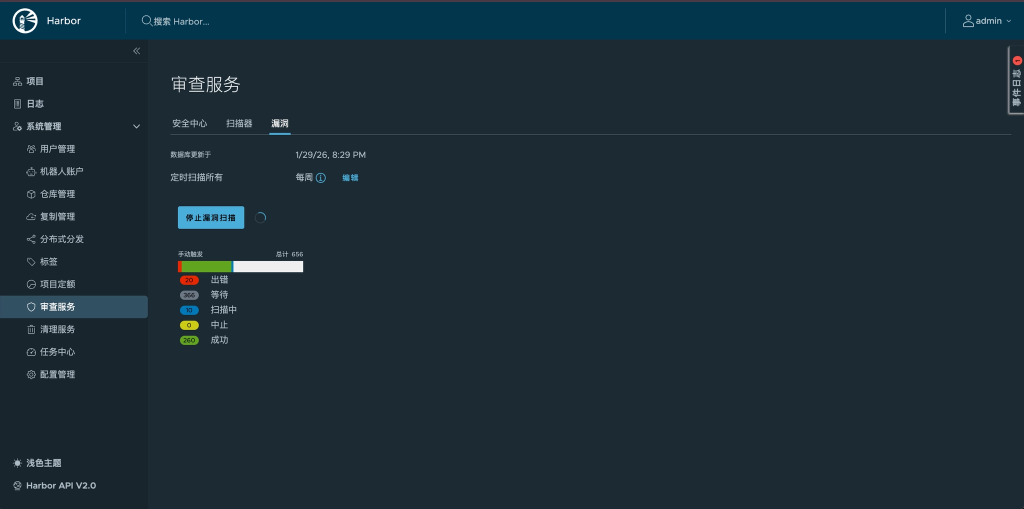
完成离线数据库导入和 Trivy 配置调整之后,最后还需要回到 Harbor 图形界面中确认扫描是否真正恢复正常。这一阶段的重点已经不再是“服务是否启动”,而是看镜像扫描结果能否在界面中正确呈现,并且不再继续报数据库同步错误。
这一步虽然简单,却非常重要。因为只有当 GUI 层面也能看到扫描结果时,才能说明 Trivy 这条链路已经从“理论上修复”变成“实际可用”。也正是在这一刻,Harbor 才开始从单纯的私有镜像仓库,进一步转变为一个同时具备镜像存储、分发和基础安全治理能力的平台组件。