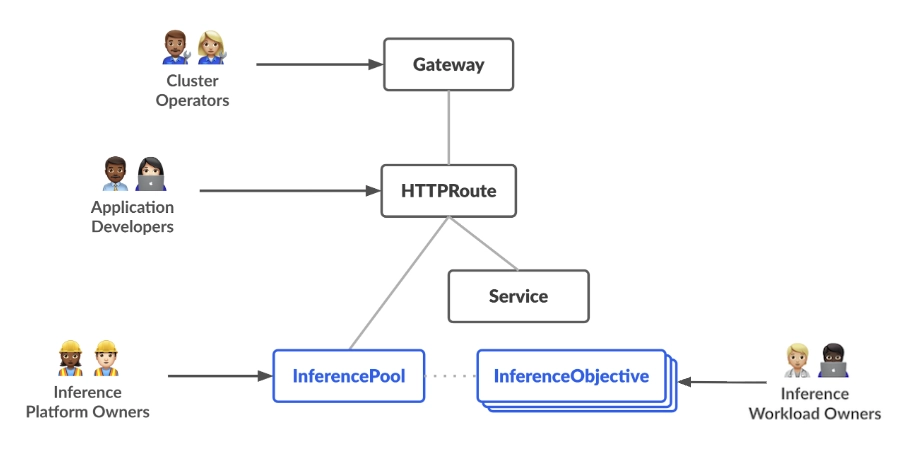
Gateway API Inference Extension 是 Kubernetes 的官方项目,用于在 Kubernetes 上更高效地自托管生成式模型。整体资源模型围绕两类新的、面向推理(inference)的角色(persona)以及他们需要管理的对应资源展开。
它的定位不是“又一个网关”,而是:在 Gateway API 体系里补齐“推理流量应该怎么选后端端点”的标准能力。重点是把“推理流量路由/负载均衡”从传统 L7 网关的通用逻辑,升级成“懂模型、懂指标、懂能力”的推理专用逻辑。
核心概念与定义
以下是该项目特定的术语定义:
| 术语 | 定义 |
|---|---|
| 推理网关 (Inference Gateway) | 一种proxy/load-balancer,与EndPointer Picker扩展进行耦合。它为在 Kubernetes 上自托管的生成式AI工作负载提供优化的路由与负载均衡能力,用于推理服务。它简化了 AI 推理工作负载的部署、管理与可观测性。这里的 “Inference Gateway”= Gateway API 实现(Envoy Gateway/kgateway/GKE Gateway 等) + ext-proc 推理扩展。网关本体负责 HTTP 转发;扩展负责“怎么选 endpoint”。 |
| 推理调度器 (Inference Scheduler) | 一个可扩展的组件,基于模型服务提供的指标(Metrics)和能力(Capabilities),为每个推理请求选择最优端点(成本最佳 / 性能最佳)。这是“决策脑”。它不是 Kubernetes 的 Pod 调度器,而是**请求级(per-request)**的端点选择器:同一个模型池里多个副本/多个节点,来一条请求要打到谁。 |
| 指标和能力 (Metrics and Capabilities) | 模型服务平台提供的关于性能、可用性和优化路由能力的特定数据。包括前缀缓存(Prefix Cache)状态或 LoRA 适配器(LoRA Adapters)可用性等信息。这是“决策的输入”。传统 LB 只看连接/RTT/健康检查;这里要看 KV cache、排队深度、适配器是否就绪、模型能力差异,因此必须定义一套可被网关侧消费的标准指标语义。 |
| 端点选择器 (Endpoint Picker, EPP) | 一种 Inference Scheduler 的实现,并额外提供路由、流控和请求控制层,用于实现更复杂的路由策略。架构细节见该项目的 EPP 架构说明。EPP 是“参考实现/默认实现”。不仅选端点,还能做**请求优先级、限流、降级(shedding)**等推理场景常见控制面能力。 |
| 基于请求体的路由器 (Body Based Router, BBR) | 一个额外的(可选)扩展实现,从推理请求的 body 中提取信息——目前是 OpenAI API 请求体里的 model name 字段——然后网关就可以做“感知模型”的功能(例如路由/调度)。BBR 可以与 EPP 一起使用,从而同时具备“模型选择(model picking)+ 端点选择(endpoint picking)”。BBR 解决的是:模型名在 body,不在 path/host/header 的现实。传统 Gateway API 的匹配主要靠 host/path/header;但 OpenAI 风格请求靠 body 的 model 字段,所以要一个扩展把 modelName 抽出来,才能做“按模型路由/灰度”。 |
关键特性
Gateway API Inference Extension 用于优化在 Kubernetes 上自托管生成式模型,提供针对推理优化的负载均衡。项目目标是在生态内改进并标准化“通往推理工作负载的路由方式”。
它通过使用 Envoy 的 External Processing(ext-proc)机制,把任何支持 ext-proc 且支持 Gateway API 的网关扩展为推理网关。该扩展可将 Envoy Gateway、kgateway、GKE Gateway 等变成推理网关,从而支持在 Kubernetes 上自托管生成式模型(当前重点是大语言模型)。这使得你可以更容易地把本地 OpenAI 兼容的 chat/completions 端点暴露给集群内/外部工作负载,或者把自托管模型与外部模型服务(model-as-a-service)一起接到更上层的 AI Gateway(如 LiteLLM、Gloo AI Gateway、Apigee)里。
这里核心是 ext-proc:网关在处理请求时,把请求的一部分(或全部)送到外部处理器(EPP/BBR),外部处理器返回决策(比如该选哪个 endpoint、是否要限流/降级等),网关据此转发。这样能做到:不改网关核心,也不绑死某一家网关实现。
该项目的目标是通过以下方式,降低 AI 工作负载的延迟并提高加速器(GPU)的利用率:
模型感知路由 (Model-aware routing):
不仅按请求路径路由,还能按模型名把请求路由到对应模型。这依赖于网关实现对 GenAI 推理 API 规范(如 OpenAI API)的支持。该能力也可扩展到 LoRA 微调模型。
💡“从 body 抽 modelName,再映射到后端 InferenceModel/adapter”的那条链路:modelName → 选择模型/版本/LoRA → 再选具体 endpoint。
服务优先级 (Serving priority):
允许您为模型指定服务优先级。例如,您可以指定对延迟敏感的在线聊天任务模型的优先级高于对延迟容忍度较高的摘要任务模型。
💡推理流量通常有明确的 SLO 分层(交互式 vs 批处理)。这意味着端点选择不只是“最快”,还要支持抢占、排队策略、丢弃低优先级请求等。
模型灰度发布 (Model rollouts):
你可以基于模型名定义流量拆分,以增量方式发布新模型版本。
💡关键点是“按模型维度”做灰度,而不是按 URL。比如 model=llama2 的请求按 90/10 分到 v1/v2,或者按某些策略逐步扩大新版本比例。
推理服务的可扩展性 (Extensibility):
推理网关为附加的推理服务定义了可扩展性模式,以便在开箱即用的解决方案不适用时创建定制的路由能力。
💡给你留了“插件口”:你可以把你们内部的调度策略(例如结合 GPU 拓扑、KV cache 命中、租户配额、SLA)塞进这个模式里,而不是只能用固定算法。
推理的自定义负载均衡 (Customizable Load Balancing):
该推理网关定义了一种优化推理的可定制 LB 与路由模式,并提供一个参考实现:利用模型服务器输出的指标来做模型端点选择。该端点选择机制可替代传统 LB。模型服务器感知的“智能负载均衡”已被证明能够降低服务延迟并提高集群加速器利用率。
💡这是最“值钱”的部分:传统 round-robin/least-conn 在 LLM 推理上经常反效果,因为每个后端的真实负载不是连接数,而是排队长度、KV cache、batch/并发、adapter 状态。所以它强调“从 model server 拉指标 → 决策 → 指挥网关转发”。
可组合的层级结构 (Composable Layers)
该项目旨在定义规范,以实现一个兼容的生态系统,通过自定义端点选择算法来扩展 Gateway API。它定义了一套跨三个不同组件层的模式:
Gateway API 实现 (Gateway API Implementations):
Gateway API 有 25+ 实现。随着该模式稳定,预计会有更多实现支持该项目并成为推理网关。 它不是绑定 Envoy Gateway 或 kgateway;只要实现支持 Gateway API + ext-proc,就能接入。
端点选择器 (Endpoint Picker):
作为项目的一部分,我们构建了Endpoint Picker:一个可插拔、可扩展的 ext-proc 部署,实现了上述架构。
模型服务器框架 (Model Server Frameworks):
项目将与模型服务框架紧密合作,建立一套共享标准来与这些扩展交互,重点是指标与可观测性,以便扩展可以做出有依据的路由决策。目前重点集成 vLLM 和 Triton,也会根据需求开放其他集成。 没有模型侧的标准指标输出,就没有“智能选端点”。所以它要推动 vLLM/Triton 等提供一致的 metric/capability 接口或约定。
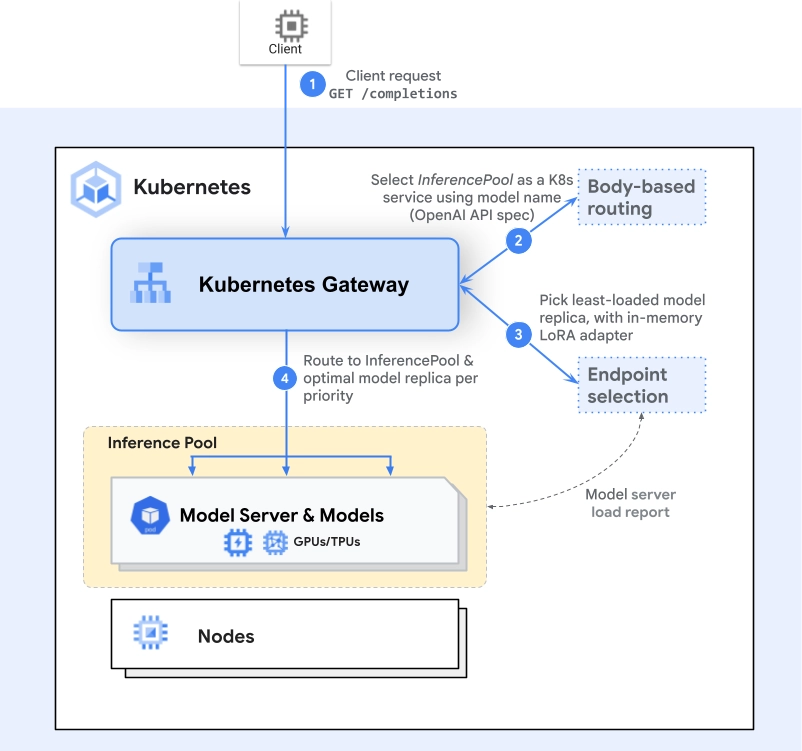
请求工作流
为了说明这些组件如何协同工作,可以通过一个示例请求来走一遍流程。
- 第一步是网关选择要路由到的正确 InferencePool(一组运行模型服务框架的端点)或 Service。这部分逻辑基于现有的 Gateway 与 HTTPRoute API,对任何 Gateway API 的使用者或实现者来说都很熟悉。
- 如果请求需要被路由到某个 InferencePool,网关会将该请求的信息转发给该 InferencePool 对应的端点选择扩展(endpoint selection extension)。
- 推理网关会从InferencePool的端点中获取指标(metrics),并从其中能够最好地实现已配置目标的那部分端点进行抓取。注意,这类指标探测可能会以异步方式发生,具体取决于推理网关的实现。
- 推理网关会指示网关:该请求应当路由到哪个端点。
- 网关将把请求路由到目标端点。