
在 AI 算力平台中,最先暴露出来的问题通常是“服务能不能跑起来”。但当集群开始承载更多训练、推理、微调任务后,真正棘手的问题会变成:有限的 GPU 资源应该如何分配。
如果说前面的章节更多关注 AI 服务如何被部署、访问和扩缩容,那么这一章要讨论的就是:当越来越多任务进入同一个 GPU 集群时,如何为 AI 算力建立一套队列秩序。
1. 为什么 AI 算力集群需要 Volcano
在单租户、业务不多、资源相对充足的集群中,默认调度器通常已经可以满足基础需求。Pod 提交后,调度器根据资源请求、节点标签、亲和性、污点容忍等条件,为 Pod 找到一个合适的节点。但 AI 算力集群的调度问题通常更复杂。
首先,GPU是稀缺资源。CPU和内存可以相对细粒度地分配,而 GPU 往往以整卡、多卡甚至整节点方式被占用。一旦调度策略不合理,就很容易出现资源碎片。例如某些节点零散剩余 1 张 GPU,但新的训练任务需要 8 张 GPU,最终看起来集群还有空闲 GPU,实际上却无法满足作业需求。
其次,AI 作业经常不是单 Pod。分布式训练通常包含 master、worker、parameter server 等多个角色;多机推理也可能包含 leader、worker、Ray head、Ray workers 等组件。这类作业如果只启动了一部分 Pod,剩余 Pod 因资源不足长期 Pending,那么已经启动的 Pod 也可能无法真正工作,反而浪费 GPU。
最后,AI 算力平台通常是多租户共享的。不同团队、不同业务、不同优先级的任务会同时进入集群。训练任务可能希望长时间占用大量 GPU,在线推理服务则通常有更高的稳定性和 SLA 要求。此时,平台不仅要调度 Pod,还要回答更高层的问题:哪个队列先获得资源?哪个任务可以等待?哪个任务可以被抢占?空闲资源是否允许被其他队列临时借用?
这些问题,本质上都不是简单的“Pod 放到哪个节点”问题,而是“有限算力资源如何在多个作业、多个队列和多个租户之间有序流转”的问题。Volcano 解决的正是这类问题。
2. Volcano 的整体架构
Volcano 与 Kubernetes 天然兼容,并遵循 Kubernetes 的资源模型和控制器模式。它在 Kubernetes 之上增加了面向批处理和 AI 作业的调度能力。
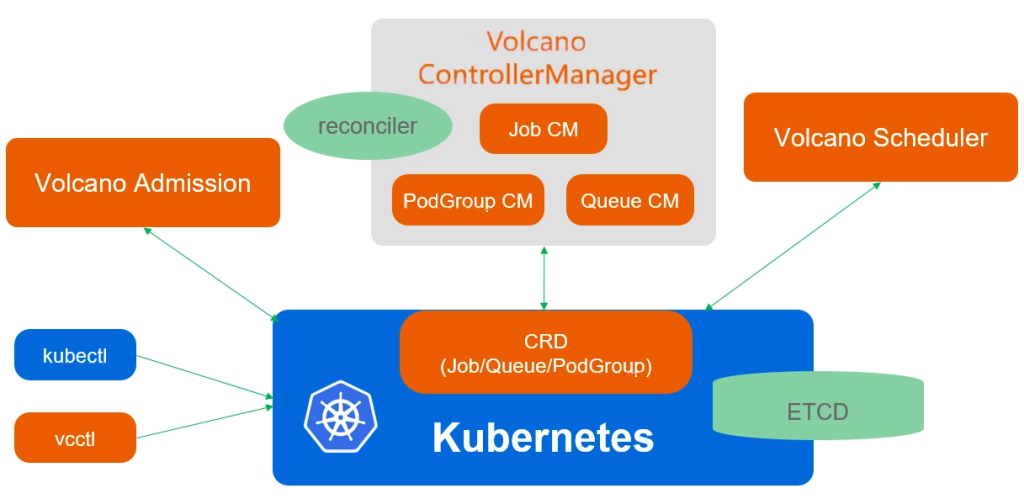
从组件上看,Volcano 主要由四部分组成:
Volcano
├── Scheduler
├── Controller Manager
├── Admission
└── vcctl
其中,Scheduler 是 Volcano 的核心组件。它通过一系列 action 和 plugin 完成调度决策,例如 enqueue、allocate、backfill、preempt、reclaim 等 action,以及 priority、gang、drf、predicates、proportion、nodeorder、binpack 等 plugin。与 Kubernetes default-scheduler 相比,Volcano 的特点是可以围绕 Job、PodGroup、Queue 等对象进行更复杂的调度决策,而不仅仅是处理单个 Pod。
Controller Manager 负责管理 Volcano CRD 资源的生命周期,例如 Queue、PodGroup、VolcanoJob 等资源。对于 AI 平台来说,Queue 和 PodGroup 是非常关键的对象:Queue 用来表达资源队列和租户边界,PodGroup 用来表达一组强关联 Pod 的整体调度关系。
Admission 负责对 Volcano 相关资源进行准入校验,保证提交到集群中的 Queue、PodGroup、Job 等资源符合预期规则。
vcctl 则是 Volcano 提供的命令行客户端工具,可以用于查看和管理 Volcano 相关资源。
在实际安装后,可以看到 Volcano 通常会在 volcano-system 命名空间下启动 admission、controllers 和 scheduler 三类核心组件:
kubectl get all -n volcano-system
输出中可以看到类似组件:
volcano-admission
volcano-controllers
volcano-scheduler
这说明 Volcano 的调度器、控制器和准入组件已经正常运行。
3. 安装 Volcano
在本文实践环境中,Volcano 使用 Helm 进行安装。由于环境中使用了私有镜像仓库,因此安装时指定了镜像仓库地址和镜像拉取策略。
首先添加 Helm 仓库:
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
# 查看可用版本:
helm search repo volcano-sh/volcano --versions
# 拉取指定版本 Chart
helm pull volcano-sh/volcano --version 1.14.0 --untar --untardir .
cd volcano
# 安装 Volcano:
# 注意,此样例使用了Harbor私有仓库
helm install volcano ./ -n volcano-system --create-namespace
--set basic.image_registry=x.x.x.101:8080
--set basic.image_pull_policy=IfNotPresent
安装完成后检查组件状态:
kubectl get all -n volcano-system
NAME READY STATUS RESTARTS AGE
pod/volcano-admission-789f84d895-lw7l6 1/1 Running 0 3m35s
pod/volcano-controllers-58cf6cd46f-tppf7 1/1 Running 0 3m35s
pod/volcano-scheduler-55fbf78788-zxc7f 1/1 Running 0 3m35s
同时也可以检查 Volcano 生成的 ConfigMap:
kubectl get configmap -n volcano-system
如果需要自定义调度策略,后续主要会修改 values.yaml 中的 scheduler_config_override,然后通过 helm upgrade 更新配置。
4. 调度配置:Action 与 Plugin
Volcano 的调度能力主要由 action 和 plugin 共同组成。action 可以理解为调度过程中的阶段,例如:
enqueue 将作业加入队列
allocate 为作业分配资源
backfill 利用空闲资源进行回填调度
preempt 处理高优先级任务的抢占
reclaim 处理队列之间的资源回收
plugin 则用于影响具体的调度判断和节点打分,例如:
priority 优先级调度
gang 成组调度
drf 主导资源公平
predicates 基础过滤条件
proportion 队列比例调度
nodeorder 节点排序
binpack 装箱调度
rescheduling 重调度
在本文实践中,调度器配置如下:
custom:
scheduler_config_override: |
actions: "enqueue, allocate, backfill, preempt, reclaim"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- plugins:
- name: proportion
- name: binpack
arguments:
binpack.weight: 10
binpack.cpu: 2
binpack.memory: 2
binpack.resources: "mars-tech.com/gpu"
"binpack.resources.mars-tech.com/gpu": 20
- name: network-topology-aware
arguments:
weight: 10
- name: rescheduling
这个配置体现了几个关键目标。
第一,启用 gang,让多 Pod 作业能够以整体方式参与调度。对于分布式训练和多机推理来说,这一点非常重要。
第二,启用 priority、preempt 和 reclaim,为高优先级任务和队列资源回收提供基础能力。当关键业务需要资源,而低优先级任务已经占用大量 GPU 时,平台可以通过优先级和抢占机制为关键任务释放资源。
第三,启用 binpack,并对 GPU 资源设置较高权重。这样 Volcano 在调度 GPU 工作负载时,会更倾向于把 Pod 尽量放到已经使用资源较多的节点上,从而减少资源碎片,把空闲节点保留下来。
更新配置后,可以通过 Helm 使配置生效:
helm upgrade volcano ./ -n volcano-system
--set basic.image_registry=112.65.216.101:8091
--set basic.image_pull_policy=IfNotPresent
-f values.yaml
检查 Volcano Scheduler 最终生效的配置:
kubectl -n volcano-system get cm volcano-scheduler-configmap
-o go-template='{{index .data "volcano-scheduler.conf"}}'
| egrep -n 'binpack|mars-tech.com/gpu'
如果输出中可以看到 binpack.weight、binpack.resources 以及 mars-tech.com/gpu,说明 GPU 装箱策略已经写入调度器配置。
5. 装箱调度(Binpack):减少 GPU 资源碎片
在 AI 集群中,GPU 资源碎片是非常常见的问题。例如,一个集群中有多个 8 卡节点。如果调度器把多个 1 卡任务分散到不同节点上,就可能导致每个节点都剩余几张 GPU,但没有任何一个节点还能满足 8 卡训练任务。这种情况下,集群表面上还有 GPU,实际却无法承载大任务。
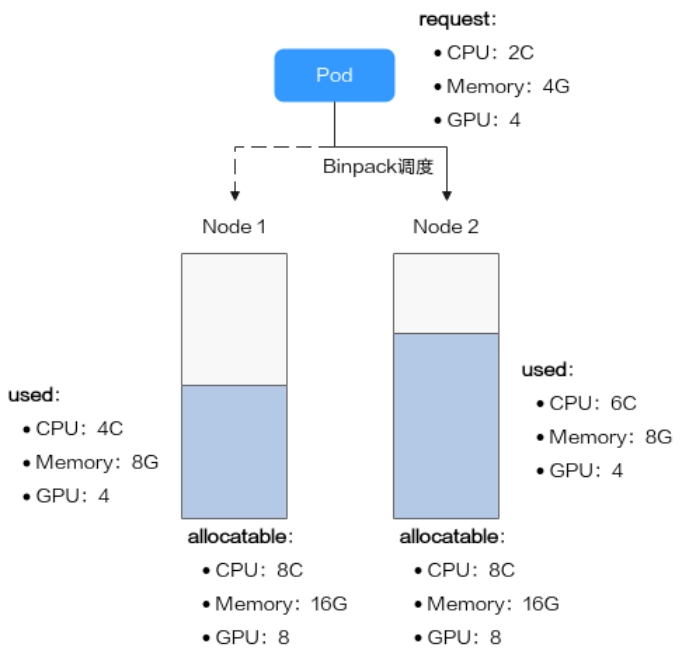
Binpack 的目标,就是尽量把负载压实到已有节点上,而不是优先摊开到更多节点。这样做的好处是:一部分节点被尽量填满,另一部分节点保持空闲,从而为后续大规格训练任务、多机任务保留更完整的资源块。
在 Volcano 中,Binpack 是一个调度插件。它会在满足基本调度条件的节点中进行打分,资源利用率越高、越符合装箱目标的节点,得分越高。本文实践中对 GPU 资源赋予了更高权重:
binpack:
arguments:
binpack.weight: 10
binpack.cpu: 2
binpack.memory: 2
binpack.resources: "mars-tech.com/gpu"
"binpack.resources.mars-tech.com/gpu": 20
这里的含义是:CPU、内存也参与打分,但 GPU 权重更高。对于 AI 算力集群来说,这种配置更符合实际需求,因为 GPU 才是最稀缺、最需要避免碎片化的资源。为了验证 Binpack 是否生效,可以创建一个使用 Volcano 调度器的 Deployment:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: demo
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen8b
namespace: demo
labels:
app: qwen8b
spec:
replicas: 1
selector:
matchLabels:
app: qwen8b
template:
metadata:
labels:
app: qwen8b
spec:
<span style="color: rgba(212, 76, 71, 1);"> schedulerName: volcano
</span> containers:
- name: qwen8b
image: 10.8.17.100:60066/mars/vllm-mars:0.11.0-hpcc.ai3.3.0.12-torch2.6-py312-ubuntu22.04-amd64-20251224
imagePullPolicy: IfNotPresent
env:
- name: CUDA_VISIBLE_DEVICES
value: "0"
- name: RAY_EXPERIMENTAL_NOSET_CUDA_VISIBLE_DEVICES
value: "1"
command: ["/bin/bash", "-lc"]
args:
- >
python -m vllm.entrypoints.openai.api_server
--model /workspace/model/Qwen3-8B
--port 8080
--tensor-parallel-size 1
--gpu-memory-utilization 0.95
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}'
--enable-auto-tool-choice
--tool-call-parser granite
--served-model-name Qwen3-8B
--trust-remote-code
--enforce-eager
ports:
- name: http
containerPort: 8080
resources:
limits:
cpu: "12"
memory: 96Gi
ephemeral-storage: 50Gi
mars-tech.com/gpu: "1"
requests:
cpu: "12"
memory: 96Gi
ephemeral-storage: 50Gi
mars-tech.com/gpu: "1"
volumeMounts:
- name: localmodelvolume
mountPath: /workspace/model
volumes:
- name: localmodelvolume
nfs:
server: 10.8.7.133
path: /zion1/nfs_csi/pvc-f74e271f-769b-420a-afe4-1a044da08fd6/pvc-f74e271f-769b-420a-afe4-1a044da08fd6
---
apiVersion: v1
kind: Service
metadata:
name: qwen8b
namespace: demo
labels:
app: qwen8b
spec:
type: NodePort
selector:
app: qwen8b
ports:
- name: http
port: 8080
targetPort: 8080
nodePort: 30180
EOF
确认 Pod 是否由 Volcano 调度:
kubectl -n demo get pod -l app=qwen8b
-o jsonpath='{.items[0].metadata.name}{" "}{.items[0].spec.schedulerName}{"n"}'
如果输出为:
qwen8b-xxxxx volcano
说明该工作负载已经交给 Volcano Scheduler 调度。
然后将副本数扩展到 6:
kubectl -n demo scale deploy qwen8b --replicas=6
kubectl get pods -n demo -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
qwen8b-77f978d58c-7stv7 1/1 Running 0 8h 192.168.4.32 gpu-worker-5 <none> <none>
qwen8b-77f978d58c-85sj6 1/1 Running 0 29s 192.168.4.34 gpu-worker-5 <none> <none>
qwen8b-77f978d58c-b4756 1/1 Running 0 29s 192.168.4.36 gpu-worker-5 <none> <none>
qwen8b-77f978d58c-bwxqc 1/1 Running 0 29s 192.168.4.33 gpu-worker-5 <none> <none>
qwen8b-77f978d58c-h7rrn 1/1 Running 0 29s 192.168.4.35 gpu-worker-5 <none> <none>
qwen8b-77f978d58c-nrdvg 1/1 Running 0 29s 192.168.4.37 gpu-worker-5 <none> <none>
kubectl -n demo get pod -l app=qwen8b -o jsonpath='{range .items[*]}{.metadata.name}{" "}{.spec.schedulerName}{"n"}{end}' | head
qwen8b-77f978d58c-7stv7 volcano
qwen8b-77f978d58c-85sj6 volcano
qwen8b-77f978d58c-b4756 volcano
qwen8b-77f978d58c-bwxqc volcano
qwen8b-77f978d58c-h7rrn volcano
qwen8b-77f978d58c-nrdvg volcano
在验证结果中,多个 qwen8b Pod 被集中调度到了同一个 GPU 节点上。这说明在当前资源请求和节点资源满足条件的前提下,Binpack 策略倾向于把 1 卡推理服务压实到已有节点,而不是分散到多个节点。这对于 AI 算力平台的价值在于小规格推理任务被集中放置,大规格训练任务和多机任务才更容易获得完整节点资源。

