
1.从 Ingress 走向 Gateway API
在传统的 Kubernetes 场景中,入口流量通常由 Ingress 处理。它提供了一个相对简单的 HTTP 入口模型,通过 Host 和 Path 将请求转发到后端 Service,这种方式在早期应用中已经被广泛采用。但 Kubernetes 社区(由 Kubernetes SIG Network 推动)已经明确:Ingress API 已进入冻结状态(feature freeze),不再新增功能,新的流量治理能力主要在 Gateway API 项目中持续演进。换句话说,Ingress 仍然可用,但其能力边界已经基本固定。
Gateway API 的变化,并不仅仅是功能增强,而是 API 设计方式的调整。与 Ingress 将入口与路由绑定在单一资源中的模型不同,Gateway API 将其拆分为独立资源:Gateway 负责定义流量如何进入集群(端口、协议、TLS 等),HTTPRoute 负责定义匹配规则与转发逻辑。这种拆分带来的关键差异在于:入口、路由以及后续策略能力不再耦合在一个对象中,而是可以分别建模和独立演进。在实际使用中,这意味着入口配置、转发规则以及扩展能力不需要在单一资源中不断叠加,从而降低了配置复杂度和变更影响范围。
在传统 Web 场景中,这种差异并不容易体现;但在 AI 平台中,这一模型差异会被放大。AI 推理流量的一个核心特征是:请求的后端选择很多时候不再是基于静态路径或域名,而是需要根据模型标识、服务状态以及调度策略动态决定。也就是说,入口层处理的问题,从“静态路由”逐渐转变为“动态调度”。
这类逻辑在 Ingress 中缺乏对应的标准字段,实际工程中通常依赖具体 Ingress Controller 的 annotations 扩展实现。这种方式不仅缺乏统一规范,也会导致配置与具体实现强绑定,从而影响可维护性和可移植性。相比之下,Gateway API 提供了一个可扩展的资源模型,使这类动态流量治理能力可以在统一接口下逐步实现,而不依赖控制器私有扩展。这也是当前多种 AI 网关实现以及 Gateway API Inference Extension 能够建立在其之上的基础。
因此,更准确的说法不是“Ingress 不再可用”,而是:Ingress 的能力已经稳定,而 Gateway API 正在成为承载复杂流量治理(尤其是 AI 推理流量)的演进方向。在 AI 平台这种入口逻辑复杂、后端动态性强的场景中,架构重心向 Gateway API 倾斜,是一个自然的技术演进过程。
到这里为止,我们讨论的仍然是流量入口的接口模型,Gateway API 解决的是“怎么描述流量应该如何被处理”,而具体“谁来处理这些流量、如何实现这些能力”,则需要落到实际的网关组件上。在当前生态中,已经出现了一批基于 Gateway API 构建的实现,包括面向通用 API 网关场景的方案,也包括针对 AI 推理场景进行扩展的网关实现。这些组件通常承担数据面(data plane)的流量处理职责,同时也可能包含对应的控制面(control plane)来管理配置与策略。也正是在这一层,方案选择开始变得不再唯一。
但在实际落地过程中可以明显感受到,这类 AI 网关项目仍处于高速演进期:组件拆分、功能边界以及项目形态都在经历剧烈的调整。笔者在早期实践中,以 kgateway 作为 AI 网关的切入点。在早期的官方文档中,kgateway 被定义为控制平面,其数据平面提供两种实现:Envoy-based proxy 与 agentgateway proxy。从官方当时释放的信息来看,在面向 AI 功能的延展上,重心明显在向 agentgateway 倾斜。基于这一预判,笔者在完成初步调研后便开始投入大量的测试验证。然而,从 2.2.x 版本开始,官方架构设计“画风突变”:agentgateway 的 API 被彻底从 kgateway 中剥离,若要继续使用 agentgateway 作为数据面,必须进行繁琐的迁移工作。紧接着,kgateway 与 agentgateway 演变为完全独立的 Helm 仓库,官方文档也随之几经变更。这种核心架构的频繁动荡与不向下兼容的调整,令人苦不堪言。 因此,这一部分的内容并不是要给出一个“唯一正确”的方案,而是基于当前实践过程,对这一类 AI 网关的角色、组合方式以及使用体验进行一次相对客观的梳理。
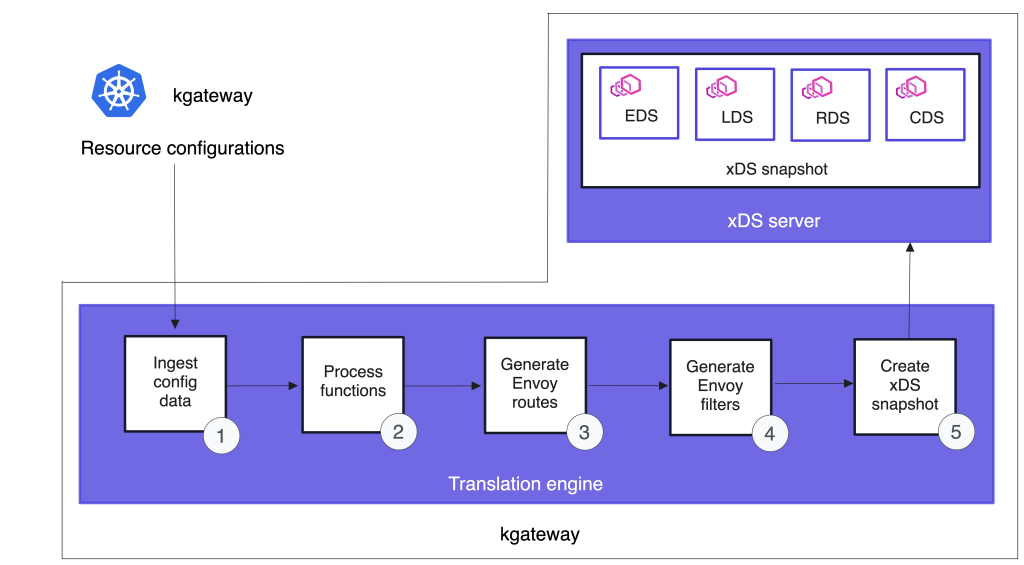
Envoy-Based Kgateway Proxy
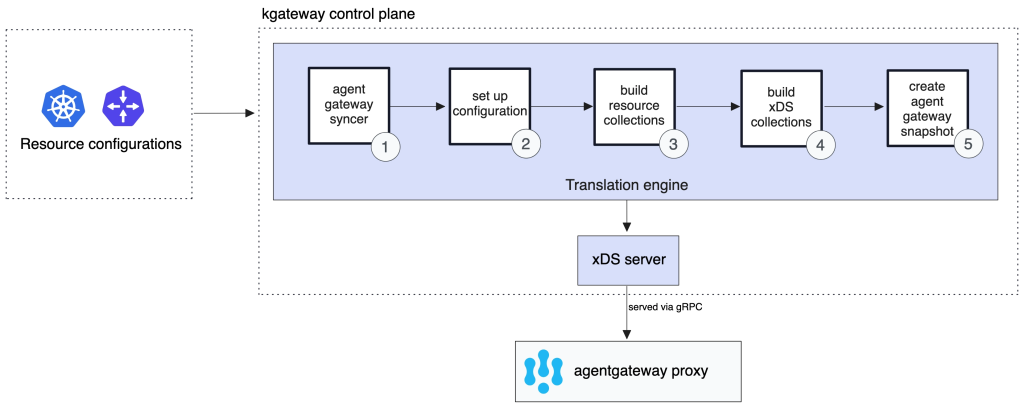
Agentgateway proxy
AI网关的功能非常丰富,笔者在此文中只聚焦在AI算力平台中非常常用功能来展开介绍。
2.AI 推理流量的智能转发
在完成从 Ingress 到 Gateway API 的入口模型演进之后,下一步要解决的问题就是AI 推理流量到底应该如何被更智能地转发到后端模型实例。
传统 Kubernetes 流量入口主要解决的是“请求如何进入集群”和“根据 Host / Path 转发到哪个 Service”。这种模型适用于普通 Web 服务,但对于大模型推理服务来说,问题远不止于此。
一次推理请求背后,实际消耗的是 GPU 显存、KV Cache、Batch 计算能力和 Token 生成能力。不同模型实例即使都处于 Ready 状态,其真实负载也可能完全不同:有的实例正在处理长上下文请求,有的实例 KV Cache 使用率较高,有的实例队列已经堆积,而有的实例仍然相对空闲。如果仍然使用传统的轮询或简单负载均衡策略,请求很可能被转发到一个“看起来可用、但实际上已经很忙”的后端,从而导致 TTFT 增大、排队时间变长,甚至触发超时。
因此,在 AI 推理场景中,入口层不应该只是一个七层转发器,而应该逐步具备推理语义感知能力。也就是说,它不仅要知道请求应该转发到哪个服务,还要能够进一步判断,这个请求应该由哪个模型、哪个副本、哪个端点来处理更合适。
Gateway API Inference Extension 正是围绕这一问题提出的。它是 Kubernetes SIG Network 生态中的官方项目,目标是在 Gateway API 之上,为 Kubernetes 上自托管生成式 AI 模型提供更优化、更标准化的推理流量路由能力。官方文档将其定位为面向自托管生成式 AI 工作负载的优化路由与负载均衡机制,重点能力包括模型感知路由、服务优先级、模型灰度发布,以及基于模型服务实时指标的自定义负载均衡。
从架构上看,Gateway API Inference Extension 并不是“又一个网关产品”。而是在 Gateway API 体系中补齐了一块过去缺失的能力:推理请求进入网关之后,应该如何选择后端端点。
在传统网关中,后端选择通常依赖静态规则,例如 Host、Path、Header、权重或连接状态。而在推理网关中,后端选择需要进一步结合模型服务的运行状态,例如队列长度、KV Cache 使用率、Prefix Cache 命中情况、LoRA Adapter 可用性,以及不同模型实例的能力差异。官方文档中也明确说明,InferencePool 表示一组推理后端,并可以与 Endpoint Picker Extension 关联,由后者基于指标与策略为请求选择更合适的后端。
换句话说,传统网关解决的是:请求能不能被转发到后端。而 AI Aware Inference Routing 要解决的是:请求应该被转发到哪个后端,才能获得更好的推理效率和资源利用率。
2.1 推理网关的核心组件
在 Gateway API Inference Extension 的设计中,整体链路可以理解为三层。
第一层仍然是 Gateway API 本身。Gateway 定义流量如何进入集群,HTTPRoute 定义请求如何匹配与转发。这一部分延续了 Gateway API 的标准资源模型,使入口流量仍然能够通过 Kubernetes 原生方式进行声明式管理。
第二层是 InferencePool。它不再像普通 Service 那样只代表一个静态后端,而是代表一组可以承载某个模型推理请求的模型服务实例。对于平台来说,InferencePool 可以被理解为一个“推理池”:池中可能有多个模型副本,分布在不同节点、不同 GPU 或不同推理引擎之上。
第三层是 Endpoint Picker Extension,也就是 EPP。EPP 是推理调度逻辑的核心组件。它会持续获取模型服务侧的指标,并在请求到来时参与端点选择。官方项目说明中也提到,Inference Gateway 是与 Endpoint Picker 结合的 proxy/load-balancer,用于为 Kubernetes 自托管生成式 AI 工作负载提供优化的路由和负载均衡能力。
因此,一条请求的逻辑链路可以抽象为:
Client
→ Gateway
→ HTTPRoute
→ InferencePool
→ Endpoint Picker Extension
→ Model Server Pod
这个链路中最关键的变化是:请求并不是简单进入一个 Service 后再由 kube-proxy 或传统负载均衡分发,而是进入 InferencePool 后,由 EPP 根据模型实例的实时状态做进一步选择。这也是 AI 推理入口与传统 Web 入口之间最本质的区别。
2.2 Inference Extension基础安装
接下来通过实际动手来看看如何完成工程实践,首先需要部署Inference Extension的CRD
💡 注意,本章节的所有配置基于2026年1月份的kgateway2.2.1,此版本开始将agentgaway的数据平面的crd做了彻底分离。
# 确认当前kgateway部署已经开启了inferenceExtension,如未开启,请参照官方部署文档
helm -n kgateway-system get values kgateway -o yaml | sed -n '1,80p'
或
helm -n kgateway-system get values agentgateway -o yaml | sed -n '1,80p'
inferenceExtension:
enabled: true
# 自动获取 Gateway API Inference Extension 项目“最新稳定版”的发布tag,避免手动指定版本。
IGW_LATEST_RELEASE=$(curl -s https://api.github.com/repos/kubernetes-sigs/gateway-api-inference-extension/releases
| jq -r '.[] | select(.prerelease == false) | .tag_name'
| sort -V
| tail -n1)
# 查看当前版本
echo "$IGW_LATEST_RELEASE"
v1.3.1
# 把Inference Extension所需的Kubernetes扩展API(CRD)安装到集群,使集群“认识”并能创建Inference相关自定义资源。
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/${IGW_LATEST_RELEASE}/manifests.yaml
customresourcedefinition.apiextensions.k8s.io/inferencemodelrewrites.inference.networking.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/inferenceobjectives.inference.networking.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/inferencepoolimports.inference.networking.x-k8s.io configured
customresourcedefinition.apiextensions.k8s.io/inferencepools.inference.networking.k8s.io configured
customresourcedefinition.apiextensions.k8s.io/inferencepools.inference.networking.x-k8s.io configured
2.3 在 vLLM 推理框架下验证 AI Aware Routing
💡 本样例以常见的单机多卡推理实例Deployment资源类型来做演示。
在实践中,首先以 vLLM 模型服务作为后端进行验证。vLLM 通过 OpenAI 兼容 API 暴露 /v1/models 和 /v1/chat/completions 接口,每个模型服务副本以 Kubernetes Deployment 的形式运行,并通过标签与 InferencePool 关联。
在模型服务部署完成后,先通过 NodePort 直连验证后端是否可用。这一步非常重要,因为只有确认模型服务本身能够正常响应,后续才能判断 Gateway、HTTPRoute、InferencePool 和 EPP 的链路问题。
当直连 /v1/models 能够返回模型 ID,直连 /v1/chat/completions 能够返回正常推理结果后,说明后端模型服务已经具备基础可用性。
kubectl apply -f - <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
aitype: tuili
name: qwen3-8b-demo
namespace: roadshow
spec:
replicas: 3
selector:
matchLabels:
app: qwen3-8b-demo
template:
metadata:
labels:
aitype: tuili
app: qwen3-8b-demo
spec:
containers:
- args:
- |
seqNum=$(expr 1 - 1)
CUDA_VISIBLE_DEVICES=$(seq -s, 0 $seqNum) /opt/conda/bin/python3 -m vllm.entrypoints.openai.api_server --model /workspace/model/Qwen3-8B --port 8080 --tensor-parallel-size 1 --gpu-memory-utilization 0.9 --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --enable-auto-tool-choice --tool-call-parser granite --served-model-name Qwen3-8B --trust-remote-code
command:
- /bin/bash
- -c
env:
- name: RAY_EXPERIMENTAL_NOSET_CUDA_VISIBLE_DEVICES
value: "1"
image: x.x.x.x/tenant_public/vllm-mars:ai3.3-torch2.6-py312-ubuntu22.04-amd64
imagePullPolicy: IfNotPresent
name: qwen3-8b-demo-container-01
resources:
limits:
cpu: "12"
ephemeral-storage: 50Gi
mars-tech.com/gpu: "1"
memory: 96Gi
requests:
cpu: "12"
ephemeral-storage: 50Gi
mars-tech.com/gpu: "1"
memory: 96Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /workspace/model
name: localmodelvolume
readOnly: true
- mountPath: /dev/shm
name: dshm
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: volcano
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /zion0/modelsrepo/models
type: Directory
name: localmodelvolume
- emptyDir:
medium: Memory
sizeLimit: 15Gi
name: dshm
---
apiVersion: v1
kind: Service
metadata:
name: qwen3-8b-demo-service
namespace: roadshow
labels:
app: qwen3-8b-demo
spec:
type: NodePort
selector:
app: qwen3-8b-demo
ports:
- name: http
port: 8080
targetPort: 8080
nodePort: 31301
EOF
# 通过内网检查验证服务可用性
curl -sS http://10.8.17.200:31301/v1/models
{"object":"list","data":[{"id":"Qwen3-8B","object":"model","created":1772164142,"owned_by":"vllm","root":"/workspace/model/Qwen3-8B","parent":null,"max_model_len":131072,"permission":[{"id":"modelperm-a82e27138dc5437484b13e3f91486070","object":"model_permission","created":1772164142,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}
curl -sS http://10.8.17.200:31301/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model":"Qwen3-8B",
"messages":[{"role":"user","content":"你好,用一句话自我介绍"}],
"temperature":0.2
}'
随后,通过 Gateway 暴露统一入口,并通过 HTTPRoute 将外部路径转发到 InferencePool。这里与普通 HTTPRoute 最大的区别在于:backendRefs 指向的不是普通 Service,而是 InferencePool。这意味着请求进入网关后,并不是被静态转发到某个 Service,而是进入推理池,由 EPP 进一步参与端点选择。
# 1. 配置监听8090端口的agentgateway网关实例
kubectl apply -f - <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: llm
namespace: kgateway-system
spec:
gatewayClassName: agentgateway
listeners:
- allowedRoutes:
namespaces:
from: All
name: http
port: 8090
protocol: HTTP
EOF
# 检查
kubectl get gateway llm -n kgateway-system
NAME CLASS ADDRESS PROGRAMMED AGE
llm agentgateway 10.8.17.152 True 69d
# 2. 配置路由
kubectl apply -f - <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
labels:
capsule.clastix.io/managed-by: hypersuite
name: qwen3-8b-demo-route
namespace: roadshow
spec:
hostnames:
- llm.xxx.cn
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: llm
namespace: kgateway-system
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: qwen3-8b-demo
filters:
- type: URLRewrite
urlRewrite:
path:
replacePrefixMatch: /
type: ReplacePrefixMatch
matches:
- path:
type: PathPrefix
value: /roadshow/qwen3-8b-demo
EOF
<span style="color: rgba(203, 145, 47, 1);"><strong># 3. 部署InferencePool与Endpoint Picker Extension</strong></span>
helm upgrade --install qwen3-8b-demo .
--namespace roadshow --create-namespace
--dependency-update
--set inferencePool.modelServers.matchLabels.app=qwen3-8b-demo
-f values.yaml
NAME: qwen3-8b-demo
LAST DEPLOYED: Fri Feb 27 04:26:17 2026
NAMESPACE: roadshow
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
TEST SUITE: None
NOTES:
InferencePool qwen3-8b-demo deployed.<span style="color: rgba(203, 145, 47, 1);
在 EPP 的默认配置中,可以看到类似如下插件组合:
# 缺省pool内使用到的负载均衡策略
kubectl -n roadshow get cm qwen3-8b-demo-epp -o yaml
apiVersion: v1
data:
default-plugins.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: queue-scorer
- type: kv-cache-utilization-scorer
- type: prefix-cache-scorer
schedulingProfiles:
- name: default
plugins:
- pluginRef: queue-scorer
weight: 2
- pluginRef: kv-cache-utilization-scorer
weight: 2
- pluginRef: prefix-cache-scorer
weight: 3
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: qwen3-8b-demo
meta.helm.sh/release-namespace: roadshow
creationTimestamp: "2026-03-13T03:31:53Z"
labels:
app.kubernetes.io/managed-by: Helm
capsule.clastix.io/managed-by: livedemo
name: qwen3-8b-demo-epp
namespace: roadshow
resourceVersion: "357726537"
uid: 7133950d-a3ba-4bba-8b3c-509c1abd1195
这个配置说明,EPP 并不是简单做轮询,而是会综合考虑队列长度、KV Cache 使用率和 Prefix Cache 相关信息,对后端端点进行评分和选择。随后通过 Gateway 地址访问 /v1/models 和 /v1/chat/completions,可以验证完整链路已经打通:
# 验证业务流程是否正常
curl -sS -H 'Host: llm.xxx.cn' http://10.8.17.152:8090/roadshow/qwen3-8b-demo/v1/models
curl -sS -H 'Host: llm.xxx.cn' http://10.8.17.152:8090/roadshow/qwen3-8b-demo/v1/chat/completions
-H 'Content-Type: application/json'
-d '{
"model":"Qwen3-8B",
"messages":[{"role":"user","content":"你好,用一句话自我介绍"}],
"temperature":0.2
}'
# 查看每个副本实际命中情况
kubectl get pods -n roadshow -o wide
qwen3-8b-demo-866dbc74c4-mjhq6 1/1 Running 0 3h57m 192.168.107.194 gpu-worker-65 <none> <none>
qwen3-8b-demo-866dbc74c4-xmz7j 1/1 Running 0 3h57m 192.168.112.49 gpu-worker-72 <none> <none>
qwen3-8b-demo-epp-679ff99955-wrg94 1/1 Running 0 33h 192.168.117.45 gpu-worker-77 <none> <none>
# 这个脚本会每秒查询一次2个 vLLM 后端 Pod 的 /metrics,实时显示每个实例当前正在处理的请求数、排队请求数、缓存使用率以及累计处理的 token。
# 它的目的是让你直观看到压测流量到底落到了哪些后端实例上,以及是否真的在多个 Pod 之间分摊。
watch -n 1 '
for ip in 192.168.107.194 192.168.112.49; do
echo "===== $ip ====="
curl -sS http://$ip:8080/metrics | egrep "vllm:num_requests_running|vllm:num_requests_waiting|vllm:gpu_cache_usage_perc|vllm:request_prompt_tokens_sum|vllm:generation_tokens_total"
echo
done
'
Every 1.0s: master-01: Sat Mar 14 13:20:08 2026
===== 192.168.107.194 =====
# HELP vllm:num_requests_running Number of requests in model execution batches.
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{engine="0",model_name="Qwen3-8B"} 0.0
# HELP vllm:num_requests_waiting Number of requests waiting to be processed.
# TYPE vllm:num_requests_waiting gauge
vllm:num_requests_waiting{engine="0",model_name="Qwen3-8B"} 0.0
# HELP vllm:generation_tokens_total Number of generation tokens processed.
# TYPE vllm:generation_tokens_total counter
vllm:generation_tokens_total{engine="0",model_name="Qwen3-8B"} 509.0
vllm:request_prompt_tokens_sum{engine="0",model_name="Qwen3-8B"} 30.0
===== 192.168.112.49 =====
# HELP vllm:num_requests_running Number of requests in model execution batches.
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{engine="0",model_name="Qwen3-8B"} 0.0
# HELP vllm:num_requests_waiting Number of requests waiting to be processed.
# TYPE vllm:num_requests_waiting gauge
vllm:num_requests_waiting{engine="0",model_name="Qwen3-8B"} 0.0
# HELP vllm:generation_tokens_total Number of generation tokens processed.
# TYPE vllm:generation_tokens_total counter
vllm:generation_tokens_total{engine="0",model_name="Qwen3-8B"} 0.0
vllm:request_prompt_tokens_sum{engine="0",model_name="Qwen3-8B"} 0.0
但对于 AI Aware Routing 来说,仅仅“请求能返回”还不够。真正关键的是:要确认 EPP 是否真的参与了调度决策。因此,需要进一步查看 EPP 暴露的 /metrics。在压测过程中,可以观察到如下几类指标:
# 验证EPP从modelserver拿到了用于选路的指标
# 通过epp的服务接口来查看是否真正拿到了modelserver的指标,队列大小会发生变化。
kubectl -n roadshow get svc qwen3-8b-demo-epp -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
qwen3-8b-demo-epp ClusterIP 10.101.199.180 <none> 9002/TCP,9090/TCP 11m inferencepool=qwen3-8b-demo-epp
curl -sS http://10.101.199.180:9090/metrics | egrep "inference_pool_ready_pods|inference_pool_per_pod_queue_size|inference_pool_average_" | head -n 80
# HELP inference_pool_average_kv_cache_utilization [ALPHA] The average kv cache utilization for an inference server pool.
# TYPE inference_pool_average_kv_cache_utilization gauge
inference_pool_average_kv_cache_utilization{name="qwen3-8b-demo"} 0.04881823810044065
# HELP inference_pool_average_queue_size [ALPHA] The average number of requests pending in the model server queue.
# TYPE inference_pool_average_queue_size gauge
inference_pool_average_queue_size{name="qwen3-8b-demo"} 48
# HELP inference_pool_per_pod_queue_size [ALPHA] The total number of requests pending in the model server queue for each underlying pod.
# TYPE inference_pool_per_pod_queue_size gauge
inference_pool_per_pod_queue_size{model_server_pod="qwen3-8b-demo-866dbc74c4-47k6n-rank-0",name="qwen3-8b-demo"} 0
inference_pool_per_pod_queue_size{model_server_pod="qwen3-8b-demo-866dbc74c4-5clwk-rank-0",name="qwen3-8b-demo"} 144
inference_pool_per_pod_queue_size{model_server_pod="qwen3-8b-demo-866dbc74c4-6hv5n-rank-0",name="qwen3-8b-demo"} 0
# HELP inference_pool_ready_pods [ALPHA] The number of ready pods in the inference server pool.
# TYPE inference_pool_ready_pods gauge
inference_pool_ready_pods{name="qwen3-8b-demo"} 3
# 查看EPP metrics,确认是否由EPP来完成了请求的决策。
# inference_extension_scheduler_attempts_total{status="success"} 5
这说明:EPP已经成功执行了5次调度决策(也就是至少有 5 次 ext-proc 调用触发了“选哪个 endpoint”)。
curl -sS http://10.101.199.180:9090/metrics | egrep -i 'ext.?proc|grpc|http|request|decision|pick|schedule' | head -n 120
# HELP go_cpu_classes_gc_mark_idle_cpu_seconds_total Estimated total CPU time spent performing GC tasks on spare CPU resources that the Go scheduler could not otherwise find a use for. This should be subtracted from the total GC CPU time to obtain a measure of compulsory GC CPU time. This metric is an overestimate, and not directly comparable to system CPU time measurements. Compare only with other /cpu/classes metrics. Sourced from /cpu/classes/gc/mark/idle:cpu-seconds.
# HELP go_godebug_non_default_behavior_http2client_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=http2client=... setting. Sourced from /godebug/non-default-behavior/http2client:events.
# TYPE go_godebug_non_default_behavior_http2client_events_total counter
go_godebug_non_default_behavior_http2client_events_total 0
# HELP go_godebug_non_default_behavior_http2server_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=http2server=... setting. Sourced from /godebug/non-default-behavior/http2server:events.
# TYPE go_godebug_non_default_behavior_http2server_events_total counter
go_godebug_non_default_behavior_http2server_events_total 0
# HELP go_godebug_non_default_behavior_httpcookiemaxnum_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=httpcookiemaxnum=... setting. Sourced from /godebug/non-default-behavior/httpcookiemaxnum:events.
# TYPE go_godebug_non_default_behavior_httpcookiemaxnum_events_total counter
go_godebug_non_default_behavior_httpcookiemaxnum_events_total 0
# HELP go_godebug_non_default_behavior_httplaxcontentlength_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=httplaxcontentlength=... setting. Sourced from /godebug/non-default-behavior/httplaxcontentlength:events.
# TYPE go_godebug_non_default_behavior_httplaxcontentlength_events_total counter
go_godebug_non_default_behavior_httplaxcontentlength_events_total 0
# HELP go_godebug_non_default_behavior_httpmuxgo121_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=httpmuxgo121=... setting. Sourced from /godebug/non-default-behavior/httpmuxgo121:events.
# TYPE go_godebug_non_default_behavior_httpmuxgo121_events_total counter
go_godebug_non_default_behavior_httpmuxgo121_events_total 0
# HELP go_godebug_non_default_behavior_httpservecontentkeepheaders_events_total The number of non-default behaviors executed by the net/http package due to a non-default GODEBUG=httpservecontentkeepheaders=... setting. Sourced from /godebug/non-default-behavior/httpservecontentkeepheaders:events.
# TYPE go_godebug_non_default_behavior_httpservecontentkeepheaders_events_total counter
go_godebug_non_default_behavior_httpservecontentkeepheaders_events_total 0
# HELP go_sched_latencies_seconds Distribution of the time goroutines have spent in the scheduler in a runnable state before actually running. Bucket counts increase monotonically. Sourced from /sched/latencies:seconds.
inference_extension_plugin_duration_seconds_bucket{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker",le="0.01"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker",le="0.02"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker",le="0.05"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker",le="0.1"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker",le="+Inf"} 5
inference_extension_plugin_duration_seconds_sum{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker"} 2.5848999999999996e-05
inference_extension_plugin_duration_seconds_count{extension_point="Picker",plugin_name="max-score-picker",plugin_type="max-score-picker"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer",le="0.0001"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer",le="0.0002"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer",le="0.0005"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer",le="0.001"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer",le="+Inf"} 5
inference_extension_plugin_duration_seconds_sum{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer"} 0.00010747600000000001
inference_extension_plugin_duration_seconds_count{extension_point="PreRequest",plugin_name="prefix-cache-scorer",plugin_type="prefix-cache-scorer"} 5
inference_extension_plugin_duration_seconds_bucket{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler",le="0.0001"} 10
inference_extension_plugin_duration_seconds_bucket{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler",le="0.0002"} 10
inference_extension_plugin_duration_seconds_bucket{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler",le="0.05"} 10
inference_extension_plugin_duration_seconds_bucket{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler",le="0.1"} 10
inference_extension_plugin_duration_seconds_sum{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler"} 4.733e-06
inference_extension_plugin_duration_seconds_count{extension_point="ProfilePicker",plugin_name="single-profile-handler",plugin_type="single-profile-handler"} 10
# HELP inference_extension_scheduler_attempts_total [ALPHA] Total number of scheduling attempts.
# TYPE inference_extension_scheduler_attempts_total counter
inference_extension_scheduler_attempts_total{status="success"} 5
# HELP inference_extension_scheduler_e2e_duration_seconds [ALPHA] End-to-end scheduling latency distribution in seconds.
# TYPE inference_extension_scheduler_e2e_duration_seconds histogram
inference_extension_scheduler_e2e_duration_seconds_bucket{le="0.0001"} 4
inference_extension_scheduler_e2e_duration_seconds_bucket{le="0.0002"} 4
inference_extension_scheduler_e2e_duration_seconds_bucket{le="0.0005"} 4
inference_extension_scheduler_e2e_duration_seconds_bucket{le="0.001"} 5
inference_extension_scheduler_e2e_duration_seconds_bucket{le="+Inf"} 5
inference_extension_scheduler_e2e_duration_seconds_sum 0.001092388
inference_extension_scheduler_e2e_duration_seconds_count 5
... ...
inference_objective_request_duration_seconds_bucket{model_name="Qwen3-8B",target_model_name="Qwen3-8B",le="1200"} 5
inference_objective_request_duration_seconds_bucket{model_name="Qwen3-8B",target_model_name="Qwen3-8B",le="1800"} 5
inference_objective_request_duration_seconds_bucket{model_name="Qwen3-8B",target_model_name="Qwen3-8B",le="2700"} 5
inference_objective_request_duration_seconds_bucket{model_name="Qwen3-8B",target_model_name="Qwen3-8B",le="3600"} 5
inference_objective_request_duration_seconds_bucket{model_name="Qwen3-8B",target_model_name="Qwen3-8B",le="+Inf"} 5
inference_objective_request_duration_seconds_sum{model_name="Qwen3-8B",target_model_name="Qwen3-8B"} 5.2231309790000005
inference_objective_request_duration_seconds_count{model_name="Qwen3-8B",target_model_name="Qwen3-8B"} 5
这些指标能够证明两件事。
第一,EPP 已经能够看到后端模型池中的 Pod 状态和队列情况。例如 inference_pool_ready_pods
表示当前推理池中 Ready 的模型实例量
inference_pool_per_pod_queue_size
可以显示每个模型 Pod 的队列大小。
第二,EPP 已经执行了调度决策。例如 inference_extension_scheduler_attempts_total{status="success"}
表示调度尝试成功次数。
inference_extension_plugin_duration_seconds
则可以看到具体插件的执行情况。
这一步非常关键。因为它证明当前链路已经不只是 Gateway 到后端的普通七层转发,而是真正进入了推理感知调度阶段。
2.3 在 SGLang推理框架下验证 AI Aware Routing
下面提供SGLang下的配置实例,由于和vLLM大致相似,不再赘述相关配置的解释。
💡 本样例以常见的单机多卡推理实例Deployment类型资源来做演示
1. 配置qwen32b的推理服务
kubectl apply -f - <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: sglang-qwen32b
namespace: demo
spec:
replicas: 1
selector:
matchLabels:
app: sglang-qwen32b
template:
metadata:
labels:
app: sglang-qwen32b
inference.networking.k8s.io/engine-type: sglang
spec:
securityContext:
seccompProfile:
type: Unconfined
containers:
- name: sglang
image: 10.8.17.100:60066/sglang/sglang:0.5.4-hpcc.ai3.3.0.13-torch2.6-py310-ubuntu22.04-amd64
imagePullPolicy: IfNotPresent
env:
- name: HPCC_SMALL_PAGESIZE_ENABLE
value: "1"
- name: PYTORCH_ENABLE_PG_HIGH_PRIORITY_STREAM
value: "1"
- name: HPCC_VISIBLE_DEVICE
value: "0,1,2,3,4,5,6,7"
- name: TRITON_ENABLE_HPCC_OPT_MOVE_DOT_OPERANDS_OUT_LOOP
value: "1"
- name: TRITON_DISABLE_HPCC_OPT_MMA_PREFETCH
value: "1"
- name: TRITON_ENABLE_HPCC_CHAIN_DOT_OPT
value: "1"
- name: TRITON_ENABLE_HPCC_COMPILER_INT8_OPT
value: "True"
- name: VLLM_PP_LAYER_PARTITION
value: "16,15,15,15"
command:
- sh
- -c
- |
/opt/conda/bin/python3 -m sglang.launch_server \
--model-path /workspace/model/Qwen3-32B \
--served-model-name Qwen3-32B \
--tp 8 \
--dp 1 \
--nnodes 1 \
--node-rank 0 \
--dist-init-addr 127.0.0.1:5000 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-dp-attention \
--enable-metrics \
--host 0.0.0.0 \
--port 8080
ports:
- name: http
containerPort: 30000
resources:
limits:
mars-tech.com/gpu: 8
requests:
mars-tech.com/gpu: 8
securityContext:
capabilities:
add:
- IPC_LOCK
volumeMounts:
- name: dshm
mountPath: /dev/shm
- name: localmodelvolume
mountPath: /workspace/model
readOnly: true
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 100Gi
- hostPath:
path: /zion0/modelsrepo/models
type: Directory
name: localmodelvolume
---
apiVersion: v1
kind: Service
metadata:
name: sglang-qwen32b
namespace: demo
spec:
type: NodePort
selector:
app: sglang-qwen32b
ports:
- name: http
port: 8080
targetPort: 8080
nodePort: 30287
EOF
# 验证
# 模型服务是否正常
curl -sS http://10.8.17.200:30287/v1/models
# 测试metrics是否暴露
curl -s http://10.8.17.200:30287/metrics | grep 'sglang:num_queue_reqs'
curl -s http://10.8.17.200:30287/metrics | grep 'sglang:num_running_reqs'
curl -s http://10.8.17.200:30287/metrics | grep 'sglang:token_usage'
# HELP sglang:num_queue_reqs The number of requests in the waiting queue.
# TYPE sglang:num_queue_reqs gauge
sglang:num_queue_reqs{engine_type="unified",model_name="/workspace/model/Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# HELP sglang:num_running_reqs The number of running requests.
# TYPE sglang:num_running_reqs gauge
sglang:num_running_reqs{engine_type="unified",model_name="/workspace/model/Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# HELP sglang:num_running_reqs_offline_batch The number of running low-priority offline batch requests(label is 'batch').
# TYPE sglang:num_running_reqs_offline_batch gauge
sglang:num_running_reqs_offline_batch{engine_type="unified",model_name="/workspace/model/Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# HELP sglang:token_usage The token usage.
# TYPE sglang:token_usage gauge
sglang:token_usage{engine_type="unified",model_name="/workspace/model/Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
2.部署网关实例
# 配置监听8090端口的agentgateway网关实例
kubectl apply -f - <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: llm
namespace: kgateway-system
spec:
gatewayClassName: agentgateway
listeners:
- allowedRoutes:
namespaces:
from: All
name: http
port: 8090
protocol: HTTP
EOF
# 检查
kubectl get gateway llm -n kgateway-system
NAME CLASS ADDRESS PROGRAMMED AGE
llm agentgateway 10.8.17.152 True 69d
3.配置路由
kubectl apply -f - <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
labels:
capsule.clastix.io/managed-by: hypersuite
name: sglang-qwen32b-route
namespace: demo
spec:
hostnames:
- llm.xxx.cn
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: llm
namespace: kgateway-system
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: sglang-qwen32b-pool
namespace: demo
filters:
- type: URLRewrite
urlRewrite:
path:
replacePrefixMatch: /
type: ReplacePrefixMatch
matches:
- path:
type: PathPrefix
value: /demo/sglang-qwen32b
EOF
4.部署InferencePool与Endpoint Picker Extension
# 通过helm安装inferencepool和epp
helm upgrade --install sglang-qwen32b-pool . \
--namespace demo --create-namespace \
--dependency-update \
--set inferencePool.modelServers.matchLabels.app=sglang-qwen32b \
--set inferencePool.modelServerType=sglang \
--set experimentalHttpRoute.enabled=false \
-f values.yaml
5. 测试与验证
# 1.验证业务流程是否正常
curl -sS http://10.8.17.152:8090/demo/sglang-qwen32b/v1/chat/completions \
-H 'Host: llm.wtsht.cn' \
-H 'Content-Type: application/json' \
-d '{
"model": "/workspace/model/Qwen3-32B",
"messages": [
{"role":"user","content":"你好,用一句话自我介绍"}
],
"temperature": 0.2
}'
# 2. 查看每个副本实际命中情况
kubectl get pods -n demo -l app=sglang-qwen32b -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sglang-qwen32b-788dd97f98-hkcx8 1/1 Running 0 17m 192.168.117.49 gpu-worker-77 <none> <none>
sglang-qwen32b-788dd97f98-ngkcr 1/1 Running 0 5m58s 192.168.19.13 gpu-worker-96 <none> <none>
# 这个脚本会每秒查询一次2个 vLLM 后端 Pod 的 /metrics,实时显示每个实例当前正在处理的请求数、排队请求数、缓存使用率以及累计处理的 token。
# 它的目的是让你直观看到压测流量到底落到了哪些后端实例上,以及是否真的在多个 Pod 之间分摊。
watch -n 1 '
for ip in 192.168.117.49 192.168.19.13; do
echo "===== $ip ====="
curl -sS http://$ip:8080/metrics | egrep "sglang:num_running_reqs|sglang:num_queue_reqs|sglang:token_usage"
echo
done
'
# 3. 执行压测
GWIP=10.8.17.152
for i in $(seq 1 100); do
curl -sS http://$GWIP:8090/demo/sglang-qwen32b/v1/chat/completions \
-H 'Host: llm.wtsht.cn' \
-H 'Content-Type: application/json' \
-d "$(cat <<EOF
{"model":"Qwen3-32B","messages":[{"role":"user","content":"请求编号 REQ-$i,请写一篇不少于2000字的自我介绍,并且每一段都要展开说明。"}],"max_tokens":1024,"temperature":0.2}
EOF
)" >/dev/null &
done
wait
在刚才执行watch的终端来查看
Every 1.0s: master-01: Mon Mar 16 15:30:10 2026
===== 192.168.117.49 =====
# HELP sglang:num_running_reqs The number of running requests.
# TYPE sglang:num_running_reqs gauge
sglang:num_running_reqs{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 43.0
# HELP sglang:token_usage The token usage.
# TYPE sglang:token_usage gauge
sglang:token_usage{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0021420527801805037
# HELP sglang:num_queue_reqs The number of requests in the waiting queue.
# TYPE sglang:num_queue_reqs gauge
sglang:num_queue_reqs{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# HELP sglang:num_running_reqs_offline_batch The number of running low-priority offline batch requests(label is 'batch').
# TYPE sglang:num_running_reqs_offline_batch gauge
sglang:num_running_reqs_offline_batch{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
===== 192.168.19.13 =====
# HELP sglang:num_running_reqs The number of running requests.
# TYPE sglang:num_running_reqs gauge
sglang:num_running_reqs{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 57.0
# HELP sglang:token_usage The token usage.
# TYPE sglang:token_usage gauge
sglang:token_usage{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0032260016823625975
# HELP sglang:num_queue_reqs The number of requests in the waiting queue.
# TYPE sglang:num_queue_reqs gauge
sglang:num_queue_reqs{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# HELP sglang:num_running_reqs_offline_batch The number of running low-priority offline batch requests(label is 'batch').
# TYPE sglang:num_running_reqs_offline_batch gauge
sglang:num_running_reqs_offline_batch{engine_type="unified",model_name="Qwen3-32B",pp_rank="0",tp_rank="0"} 0.0
# 4.查看epp对应metric记录
kubectl get svc sglang-qwen32b-pool-epp -n demo -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
sglang-qwen32b-pool-epp ClusterIP 10.96.60.237 <none> 9002/TCP,9090/TCP 50m inferencepool=sglang-qwen32b-pool-epp
curl -sS http://10.96.60.237:9090/metrics | egrep "inference_pool_ready_pods|inference_pool_per_pod_queue_size|inference_pool_average_"
# HELP inference_pool_average_kv_cache_utilization [ALPHA] The average kv cache utilization for an inference server pool.
# TYPE inference_pool_average_kv_cache_utilization gauge
inference_pool_average_kv_cache_utilization{name="sglang-qwen32b-pool"} 0
# HELP inference_pool_average_queue_size [ALPHA] The average number of requests pending in the model server queue.
# TYPE inference_pool_average_queue_size gauge
inference_pool_average_queue_size{name="sglang-qwen32b-pool"} 0
# HELP inference_pool_per_pod_queue_size [ALPHA] The total number of requests pending in the model server queue for each underlying pod.
# TYPE inference_pool_per_pod_queue_size gauge
inference_pool_per_pod_queue_size{model_server_pod="sglang-qwen32b-788dd97f98-hkcx8-rank-0",name="sglang-qwen32b-pool"} 0
inference_pool_per_pod_queue_size{model_server_pod="sglang-qwen32b-788dd97f98-ngkcr-rank-0",name="sglang-qwen32b-pool"} 0
# HELP inference_pool_ready_pods [ALPHA] The number of ready pods in the inference server pool.
# TYPE inference_pool_ready_pods gauge
inference_pool_ready_pods{name="sglang-qwen32b-pool"} 2


