
1. 指标可视化:从“能访问”走向“可运营”
推理入口真正进入平台化阶段后,不能只停留在“服务能访问”。更重要的是要能回答以下问题:
- 当前有多少请求进入模型服务?
- 每个模型消耗了多少输入 Token 和输出 Token?
- 每个推理实例的队列长度是多少?
- KV Cache 使用率是否过高?
- EPP 是否正常执行调度?
- 不同模型、不同租户、不同调用方的资源消耗如何统计?
因此,指标采集与可视化是 AI 推理平台必不可少的一部分。在实践中,可以分别对 EPP、vLLM 和 SGLang 配置 Prometheus 采集。
EPP 侧主要关注推理池状态、调度行为和请求级统计指标,例如:
inference_pool_ready_pods 表示推理池中 Ready 的模型实例数量;
inference_pool_average_queue_size 表示推理池平均等待队列长度;
inference_pool_per_pod_queue_size 可以观察每个模型 Pod 的队列情况;
inference_pool_average_kv_cache_utilization 用于观察推理池整体 KV Cache 使用率;
inference_extension_scheduler_attempts_total 可以用于确认EPP是否真正执行了调度决策。
inference_objective_request_total
inference_objective_request_error_total
inference_objective_request_duration_seconds
inference_objective_input_tokens
inference_objective_output_tokens
需要特别注意的是,inference_objective_input_tokens 和 inference_objective_output_tokens 在 EPP 中属于分布类指标,Prometheus 中会派生出 _bucket、_sum、_count 等序列。其中,_count 表示样本数量,并不等于 Token 总量。如果要统计单位时间内的输出 Token,更适合使用:
sum(increase(inference_objective_output_tokens_sum[1h]))
如果要统计单位时间内的输入 Token,可以使用:
sum(increase(inference_objective_input_tokens_sum[1h]))
但这里也要注意,EPP 侧的请求级 Token 统计依赖响应中的 usage 信息。在流式响应场景下,需要确认模型服务是否返回了 usage 信息。例如 vLLM 的 streaming 请求通常需要携带:
{
"stream_options": {
"include_usage":true
}
}
否则响应侧 Token 统计可能不完整。
vLLM 侧主要关注请求状态、KV Cache、Token 计数和请求延迟,例如:
vllm:num_requests_running
vllm:num_requests_waiting
vllm:kv_cache_usage_perc
vllm:prompt_tokens_total
vllm:generation_tokens_total
vllm:time_to_first_token_seconds
vllm:inter_token_latency_seconds
vllm:e2e_request_latency_seconds
其中,vllm:prompt_tokens_total 和 vllm:generation_tokens_total 是累计 Counter,可以用于输入 Token 和输出 Token 的统计;vllm:kv_cache_usage_perc 用于观察 KV Cache 使用比例;vllm:num_requests_running 和 vllm:num_requests_waiting 用于观察运行中请求和等待队列。不同 vLLM 版本中部分指标命名可能存在差异,实际应以 /metrics 输出为准。
SGLang 侧主要关注运行中请求、等待队列、KV Cache / token capacity 使用率,以及输入输出 Token 计数,例如:
sglang:num_running_reqs
sglang:num_queue_reqs
sglang:token_usage
sglang:prompt_tokens_total
sglang:generation_tokens_total
sglang:time_to_first_token_seconds
sglang:time_per_output_token_seconds
sglang:e2e_request_latency_seconds
其中,sglang:prompt_tokens_total 和 sglang:generation_tokens_total 可以用于输入/输出 Token 统计;sglang:num_queue_reqs 表示等待队列中的请求数;sglang:num_running_reqs 表示当前运行中的请求数;sglang:token_usage 更适合理解为 KV Cache / token capacity 使用率,而不是累计 Token 用量。
这些指标的意义不仅在于展示系统状态,更重要的是为平台运营提供数据基础。例如,vLLM 的 Token 统计可以写成:
sum(increase(vllm:prompt_tokens_total[1h]))
+
sum(increase(vllm:generation_tokens_total[1h]))
SGLang 也可以通过类似方式统计单位时间内的输入和输出 Token:
sum(increase(sglang:prompt_tokens_total[1h]))
+
sum(increase(sglang:generation_tokens_total[1h]))
如果要观察推理池排队情况,可以使用:
sum by (name) (inference_pool_average_queue_size)
如果要观察每个模型 Pod 的队列分布,可以使用:
sum by (name, model_server_pod) (inference_pool_per_pod_queue_size)
如果要确认 EPP 是否持续参与调度,可以使用:
sum by (status) (rate(inference_extension_scheduler_attempts_total[5m]))
当这些指标进入 Prometheus 和 Grafana 后,推理平台就具备了进一步做容量规划、压测分析、SLA 观测、异常定位和自动扩缩容的基础。这意味着平台建设已经从“能部署模型”,开始走向“能运营模型”。下面来看具体的工程实践。
1.1 配置指标采集
本文使用 Prometheus Operator 的 ServiceMonitor 采集 EPP、vLLM 和 SGLang 的 /metrics 指标。
# 需要监控epp的metric,将epp服务打上标签,
kubectl -n roadshow label svc qwen3-8b-demo-epp scrape=epp --overwrite
# 配置通用的服务监控来监控所有的epp服务
kubectl apply -f - <<'EOF'
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: epp-metrics-all
namespace: monitoring
labels:
release: prometheus-stack
spec:
namespaceSelector:
any: true
selector:
matchLabels:
scrape: epp
endpoints:
- port: http-metrics
path: /metrics
interval: 10s
EOF
# 需要监控vLLM的metric,将vllm服务打上标签,
kubectl -n roadshow label svc qwen3-8b-demo-service scrape=vllm --overwrite
# 配置通用的服务监控来监控所有的vllm业务
kubectl apply -f - <<'EOF'
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: vllm-services-all
namespace: monitoring
labels:
release: prometheus-stack
spec:
namespaceSelector:
any: true
selector:
matchLabels:
scrape: vllm
endpoints:
- port: http
path: /metrics
interval: 10s
scheme: http
EOF
# # 需要监控SGLang的metric,将sglang服务打上标签,
kubectl -n demo label svc sglang-qwen32b scrape=sglang --overwrite
# 配置通用的服务监控来监控所有的sglang业务
kubectl apply -f - <<'EOF'
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: sglang-services-all
namespace: monitoring
labels:
release: prometheus-stack
spec:
namespaceSelector:
any: true
selector:
matchLabels:
scrape: sglang
endpoints:
- port: http
path: /metrics
interval: 10s
scheme: http
EOF
1.2 在 Prometheus 上验证指标
ServiceMonitor 创建完成后,可以先获取 Prometheus 的 ClusterIP:
PROM_IP=$(kubectl -n monitoring get svc kps-prometheus -o jsonpath='{.spec.clusterIP}')
首先验证 EPP 调度指标是否进入 Prometheus:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (status) (rate(inference_extension_scheduler_attempts_total[5m]))'
如果能够返回按 status 聚合的结果,说明 EPP 调度相关指标已经被采集。
继续验证推理池平均队列:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (name) (inference_pool_average_queue_size)'
验证每个模型 Pod 的队列分布:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (name, model_server_pod) (inference_pool_per_pod_queue_size)'
验证推理池 Ready Pod 数量:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (name) (inference_pool_ready_pods)'
如果需要验证 EPP 侧输出 Token 的分布样本,可以查询:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum(inference_objective_output_tokens_count)'
这里返回的值只能说明 EPP 观察到了多少个 output token 统计样本,不能理解为输出 Token 总量。
如果要查看 EPP 侧统计到的输出 Token 增量,应使用:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum(increase(inference_objective_output_tokens_sum[1h]))'
然后验证 vLLM 输出 Token Counter:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (vllm:generation_tokens_total)'
验证 vLLM 输入 Token Counter:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (vllm:prompt_tokens_total)'
验证 vLLM 当前运行中请求数和等待队列:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (vllm:num_requests_running)'
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (vllm:num_requests_waiting)'
验证 vLLM KV Cache 使用率:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=avg by (model_name) (vllm:kv_cache_usage_perc)'
不同版本可能存在指标命名差异。如果当前 vLLM 版本暴露的是 vllm:gpu_cache_usage_perc,则可以使用下面的查询:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=avg by (model_name) (vllm:gpu_cache_usage_perc)'
验证 SGLang 输出 Token Counter:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (sglang:generation_tokens_total)'
验证 SGLang 输入 Token Counter:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (sglang:prompt_tokens_total)'
验证 SGLang 当前运行中请求数和等待队列:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (sglang:num_running_reqs)'
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=sum by (model_name) (sglang:num_queue_reqs)'
验证 SGLang token capacity / KV Cache 使用率:
curl -sS -G "http://$PROM_IP:9090/api/v1/query"
--data-urlencode 'query=avg by (model_name) (sglang:token_usage)'
通过这些查询,可以分别确认 EPP、vLLM 和 SGLang 三类指标是否已经进入 Prometheus。后续 Grafana Dashboard、容量分析和告警规则,都可以基于这些指标继续展开。
1.3 在 Grafana 中查看 Dashboard
Gateway API Inference Extension 官方仓库中提供了 Grafana Dashboard 示例,可参考如下链接
可以将该 JSON 导入 Grafana,用于查看 Inference Gateway 相关指标,包括推理池状态、EPP 调度情况、请求量、延迟和 Token 分布等。不过在实际环境中,Dashboard 往往还需要根据 Prometheus 的标签体系进行调整。例如,不同集群中 job、namespace、service、pod、model_name 等标签可能不完全一致。如果导入 Dashboard 后没有数据,通常需要先在 Prometheus 中确认原始指标是否存在,再调整 Dashboard 变量或 PromQL 查询条件。
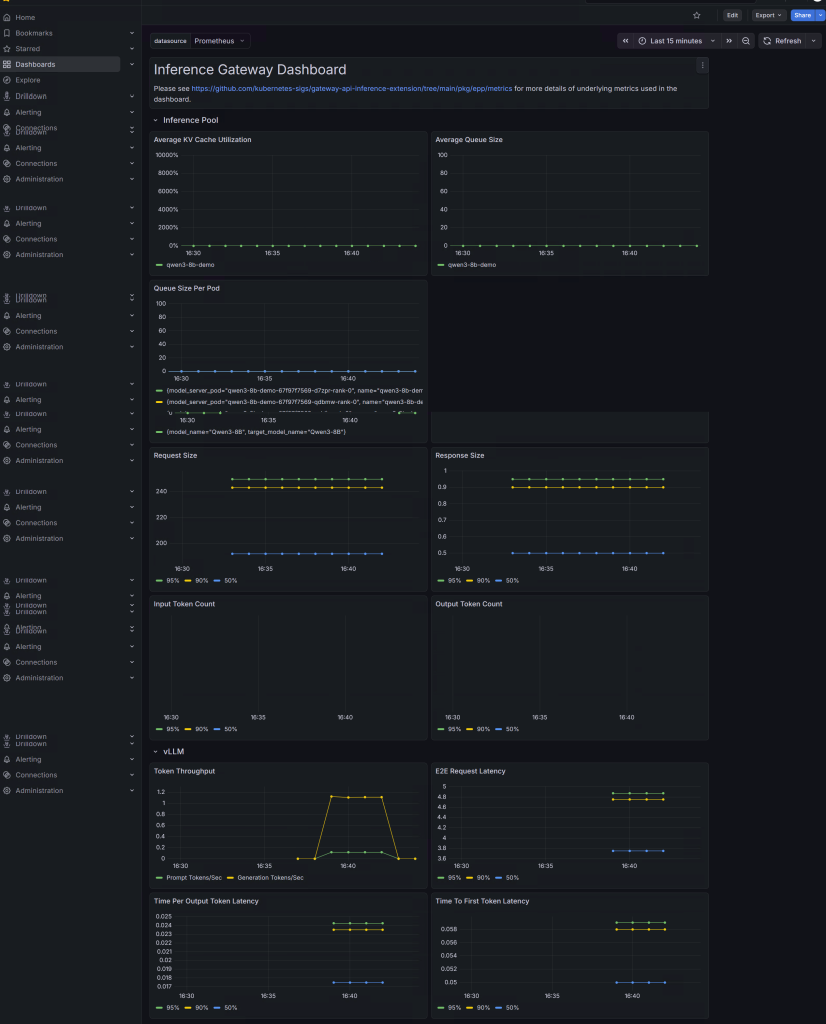
这些指标最终服务的不是“监控展示”本身,而是平台运营能力:容量规划、压测分析、SLA 观测、异常定位、成本核算和自动扩缩容。只有当这些指标能够被持续采集、查询和可视化,AI 推理平台才真正从“能访问”进入“可运营”的阶段。
2. API Key:把北向认证收敛到网关层
当模型服务从内部测试走向对外开放时,访问控制就成为必须考虑的问题。如果每个模型服务都独立实现认证逻辑,平台后续会面临很大的治理成本:不同模型的认证方式不一致,不同团队维护不同密钥逻辑,审计和权限控制也很难统一。
更合理的方式是将北向认证收敛到网关层。也就是说,所有外部调用方先经过统一入口,由网关完成 API Key 校验,只有通过认证的请求才会进入后端模型服务。
在实践中,可以通过 Kubernetes Secret 保存客户端 API Key,再通过 AgentgatewayPolicy 将 API Key 认证策略绑定到对应的 HTTPRoute 上。这样,请求必须携带合法的key才能访问后端模型服务。
Authorization: Bearer <api-key>
这种做法的价值不只是“挡住非法请求”,更重要的是把访问控制从模型服务中解耦出来。后端 vLLM 或 SGLang 只负责推理,北向认证、后续限流、审计和租户治理都可以逐步沉淀在网关层。对于多模型、多租户、多调用方的 AI 平台来说,这是入口治理的基础能力。
接下来我们尝试使用 agentgateway 的 AgentgatewayPolicy 为模型服务增加 API Key 认证能力。agentgateway 官方文档中也明确提供了 API key auth 能力:通过 Kubernetes Secret 保存 API Key,再由 AgentgatewayPolicy 引用该 Secret,并在请求进入后端之前完成认证校验;如果请求缺少有效 API Key,代理会直接返回 401 Unauthorized。
2.1 创建 Gateway 入口
首先创建一个 Gateway 实例,作为模型服务的统一北向入口。这里使用 agentgateway 作为 gatewayClassName,并监听 8090 端口。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: llm
namespace: agentgateway-system
spec:
gatewayClassName: agentgateway
listeners:
- name: http
protocol: HTTP
port: 8090
allowedRoutes:
namespaces:
from: All
这一层解决的是“请求从哪里进入集群”的问题。后续所有路由和认证策略,都会挂接在这个入口之上。
2.2 定义模型后端
接下来创建 AgentgatewayBackend,用于描述真实的模型服务后端。在这个示例中,后端是一个 OpenAI 兼容的模型服务,请求会被转发到:qwen8b.demo.svc.cluster.local:8080/v1/chat/completions
apiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayBackend
metadata:
name: qwen8b-openai
namespace: demo
spec:
ai:
provider:
host: qwen8b.demo.svc.cluster.local
port: 8080
path: /v1/chat/completions
openai:
model: Qwen3-8B
policies:
ai:
routes:
'*': Passthrough
/v1/chat/completions: Completions
/v1/embeddings: Passthrough
/v1/models: Passthrough
AgentgatewayBackend 是 agentgateway 在 Kubernetes 模式下提供的核心自定义资源之一。这里的重点是,后端模型服务本身不需要直接对外暴露,外部请求统一先进入 agentgateway,再由网关转发到后端服务。
2.3. 创建 HTTPRoute
有了入口和后端之后,需要通过 HTTPRoute 将外部路径和后端资源关联起来。这里将外部路径:/demo/qwen8b转发到刚才创建的 AgentgatewayBackend。
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: qwen8b-openai-route
namespace: demo
spec:
parentRefs:
- name: llm
namespace: agentgateway-system
rules:
- matches:
- path:
type: PathPrefix
value: /demo/qwen8b
filters:
- type: URLRewrite
urlRewrite:
path:
replacePrefixMatch: /
type: ReplacePrefixMatch
backendRefs:
- group: agentgateway.dev
kind: AgentgatewayBackend
name: qwen8b-openai
namespace: demo
port: 8080
这里使用了 URLRewrite,将外部访问路径 /demo/qwen8b 重写为 /。这样外部路径可以保持平台侧统一规划,而后端仍然按照 OpenAI 兼容接口接收请求。
2.4 创建 API Key Secret
接下来创建用于认证的API Key,推荐将 API Key 存储在 Kubernetes Secret 中,再通过 AgentgatewayPolicy 引用这些 Secret。这样做的好处是:认证凭证不需要写在路由或后端配置里,而是由 Secret 统一维护。在这个示例中,创建了一个 Kubernetes Secret,将客户端可用的 key 保存进去。
apiVersion: v1
kind: Secret
metadata:
name: llm-client-api-keys
namespace: demo
type: Opaque
stringData:
clientA: "k-123"
需要注意的是,API Key 本身属于长期凭证,实际生产环境中还需要配合密钥轮换、权限分级和审计能力。所以使用 API Key 时,服务安全性取决于 API Key 本身的保存与轮换方式。
2.5. 创建认证策略
最后创建 AgentgatewayPolicy,将 API Key 认证策略挂接到前面的 HTTPRoute 上。
apiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayPolicy
metadata:
name: qwen8b-require-api-key
namespace: demo
spec:
targetRefs:
- group: gateway.networking.k8s.io
kind: HTTPRoute
name: qwen8b-openai-route
traffic:
apiKeyAuthentication:
mode: Strict
secretRef:
name: llm-client-api-keys
这里使用的是 Strict 模式。在该模式下,请求必须携带有效 API Key,否则 agentgateway 会直接拒绝请求并返回 401 Unauthorized。官方文档中也明确说明,Strict 模式要求请求中必须包含有效的 Authorization Header;缺少或无效时,请求会被拒绝。从链路上看,认证逻辑发生在请求进入后端模型服务之前。这意味着后端模型服务本身不需要实现 API Key 校验,北向访问控制可以统一收敛到网关层完成。
2.6 访问验证
策略创建完成后,可以通过几组请求验证认证是否生效。首先获取 Gateway 地址:
GW_IP=$(kubectl -n agentgateway-system get gateway llm
-o jsonpath='{.status.addresses[0].value}')
2.6.1 使用正确 Bearer Token
curl -i "http://$GW_IP:8090/demo/qwen8b"
-H "Content-Type: application/json"
-H "Authorization: Bearer k-123"
-d '{
"model":"Qwen3-8B",
"messages":[
{
"role":"user",
"content":"您好,你是什么模型"
}
]
}'
如果 API Key 正确,请求会被放行,并转发到后端模型服务。
2.6.2 使用错误 Bearer Token
curl -i "http://$GW_IP:8090/demo/qwen8b"
-H "Content-Type: application/json"
-H "Authorization: Bearer k-wrong"
-d '{
"model":"Qwen3-8B",
"messages":[
{
"role":"user",
"content":"您好,你是什么模型"
}
]
}'
返回结果如下:
HTTP/1.1 401 Unauthorized
api key authentication failure: invalid credentials
这说明请求虽然携带了 Authorization Header,但 key 与 Secret 中保存的值不匹配,因此被拒绝。
2.6.3 使用 x-api-key Header
curl-i"http://$GW_IP:8090/demo/qwen8b"
-H"Content-Type: application/json"
-H"x-api-key: k-123"
-d'{
"model":"Qwen3-8B",
"messages":[
{
"role":"user",
"content":"hi"
}
]
}'
返回结果如下:
HTTP/1.1 401 Unauthorized
api key authentication failure: no API Key found
这说明在当前配置下,agentgateway 并没有从 x-api-key Header 中读取凭证,而是期望从 Authorization Header 中获取 API Key。
2.6.4 不携带 API Key
curl-i"http://$GW_IP:8090/demo/qwen8b"
-H"Content-Type: application/json"
-d'{
"model":"Qwen3-8B",
"messages":[
{
"role":"user",
"content":"hi"
}
]
}'
返回结果如下:
HTTP/1.1 401 Unauthorized
api key authentication failure: no API Key found
这说明 Strict 模式已经生效:没有 API Key 的请求不会被转发到后端模型服务。
通过这一组配置,可以在 agentgateway 上完成一个最基础的北向 API Key 认证闭环,这也是AI 平台对外提供模型服务时一个必须具体的能力。
最后,总结一下。Kubernetes 上的模型服务入口正在经历一个明显变化:从传统 HTTP 路由,逐步走向具备推理语义感知能力的 AI Gateway。
在最基础的阶段,Gateway 和 HTTPRoute 解决的是统一入口和路径转发问题;引入 InferencePool 后,后端不再只是普通 Service,而是一组可以被推理调度的模型实例;引入 EPP 后,入口层开始能够基于队列、KV Cache、Prefix Cache 等指标做端点选择;再结合 API Key、Body Based Router、模型灰度和指标可视化,推理入口就逐渐具备了平台化治理能力。
这套体系的价值不在于“把模型暴露出去”,而在于把推理服务变成一种可治理、可观测、可调度、可演进的基础设施能力。因此,对于一个面向多模型、多租户、多推理引擎的云原生 AI 算力平台来说,推理入口不应该只是南北向流量入口,而应该成为连接用户请求、模型服务、GPU 资源和平台治理能力的核心控制点。这也是 Gateway API Inference Extension 这类项目真正有价值的地方:它让 Kubernetes 的流量入口,从“能转发请求”,进一步走向“懂推理、能调度、可运营”的 AI 基础设施入口。


