
在传统 Web 服务中,一个副本通常可以简单理解为一个 Pod。Pod 启动后即可对外提供服务,多个副本之间相对独立,Deployment 只需要保证期望数量的 Pod 正常运行即可。但在大模型分布式推理场景中,一个完整的推理副本可能由多个 Pod 共同组成:通常会有一个负责对外提供 API、协调分布式运行的主控 Pod,也会有多个负责承载模型分片、GPU 计算或分布式执行任务的工作 Pod。对于外部用户来说,这些 Pod 组合在一起,才构成一个完整可用的模型服务实例。
如果仍然使用普通 Deployment 来管理这类工作负载,就会遇到几个问题:多个 Pod 之间缺少明确的关联关系,同一个副本组内不同 Pod 的生命周期难以保持一致;滚动更新时可能只更新了部分 Pod,导致组内版本、启动参数或运行状态不一致;某个 Pod 失败后,整个分布式推理组可能进入不一致状态;扩容时真正需要增加的是一整组推理副本,而不是单独增加某一个 Pod;服务暴露时通常也只希望暴露主控 Pod,而不是把流量直接打到所有工作 Pod。
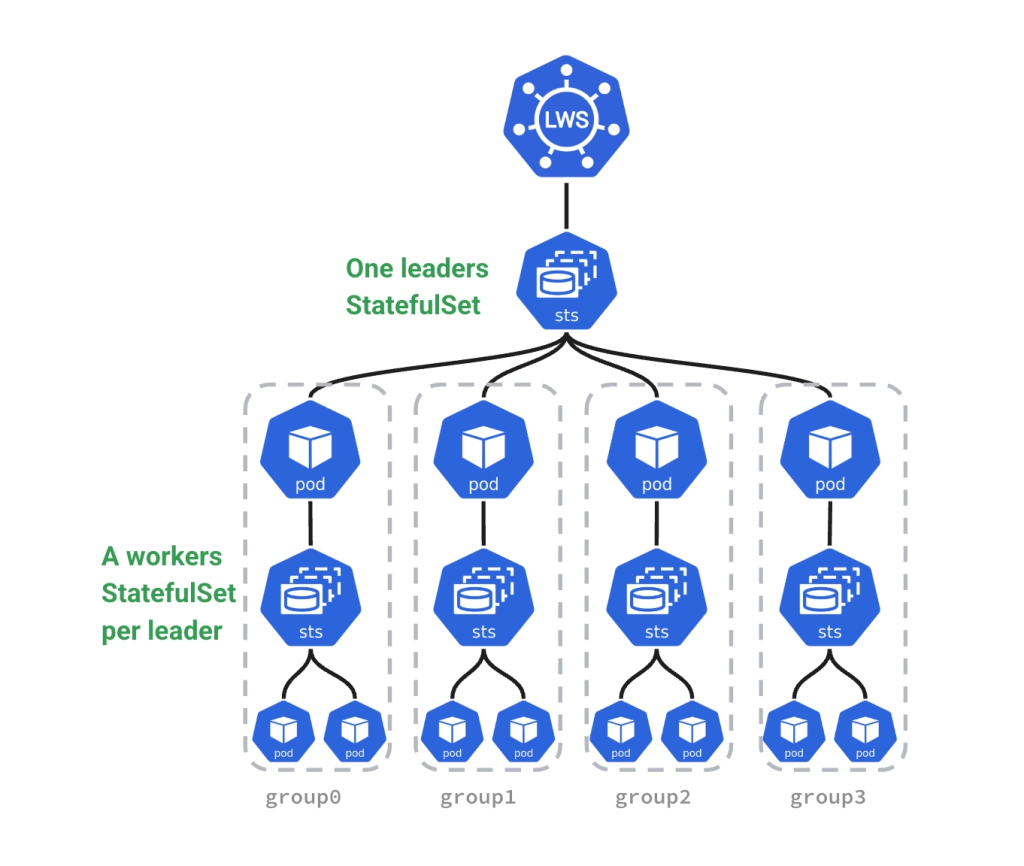
LeaderWorkerSet 正是为这类场景设计的。它是一个 Kubernetes 工作负载 API,用来把一组协同工作的 Pod 表达成一个整体。在 LWS 中,一个副本不再等同于一个 Pod,而是一个 Pod group。这个 group 通常由一个 leader 和多个 workers 组成:
1 个 leader Pod + 多个 worker Pods = 1 个 Pod group = 1 个完整的分布式推理副本
其中,leader 对应前面提到的主控角色,通常用于承载对外 API、Ray head、worker 注册协调以及分布式推理任务组织;workers 则对应工作角色,负责加入分布式运行环境、加载模型分片、使用 GPU 执行推理计算。这样一来,Kubernetes 管理的边界就从单个 Pod 提升到了整个 Pod group。
因此,LWS 的意义不只是“创建多个 Pod”,而是把这些 Pod 之间的协作关系变成 Kubernetes 可以理解和管理的工作负载边界。哪些 Pod 属于同一个推理副本,哪些 Pod 需要一起创建、一起更新、一起恢复,扩容时应该增加哪一组,缩容时应该删除哪一组,都可以围绕 group 这个边界来处理。
对于多机推理来说,这个差异非常重要。因为一个模型服务的最小运行单元,可能已经不再是单个 Pod,而是一组需要共同启动、共同运行、共同更新和共同恢复的 Pod。
1. LeaderWorkerSet 的核心模型
LeaderWorkerSet 可以简单理解为:
LeaderWorkerSet = N 个 group
每个 group = 1 个 leader Pod + 多个 worker Pod
spec.replicas 表示 group 的数量
leaderWorkerTemplate.size 表示每个 group 内 Pod 的总数
例如:这表示当前只有一个分布式推理副本组,每个组里有 6 个 Pod:1 个 leader 5 个 worker
spec:
replicas: 1
leaderWorkerTemplate:
size: 6
如果把 replicas 改成 2,就不是简单增加一个 worker,而是增加第二整组分布式推理副本:
group 0:
vllm-0
vllm-0-1
vllm-0-2
vllm-0-3
vllm-0-4
vllm-0-5
group 1:
vllm-1
vllm-1-1
vllm-1-2
vllm-1-3
vllm-1-4
vllm-1-5
这就是 LWS 和普通 Deployment 最大的区别。Deployment 的副本单位是 Pod;LeaderWorkerSet 的副本单位是 group。对于大模型多机推理来说,这个差异非常关键。因为一个模型副本本身就可能由多个 Pod 组成,不能把这些 Pod 当作互相独立的普通副本来管理。
2. LWS 的底层实现:用 StatefulSet 组织分布式推理组
从 Kubernetes 资源层面看,LeaderWorkerSet 并不是凭空创造一套全新的 Pod 管理机制,而是通过控制器组织多个 StatefulSet 来实现 leader / worker 的生命周期管理。在一个典型 LWS 中,会看到两类 StatefulSet。
第一类是 leader StatefulSet。
它负责创建每个 group 的 leader Pod。整个 LWS 通常只有一个 leader StatefulSet,这个 StatefulSet 的副本数等于 spec.replicas。也就是说:leader StatefulSet replicas = LWS group 数量
例如:每个 leader Pod 对应一个 group。
vllm StatefulSet
→ vllm-0
→ vllm-1
→ vllm-2
第二类是 worker StatefulSet。
每个 leader Pod 都会对应一个 worker StatefulSet。例如:
vllm-0 leader
→ vllm-0 worker StatefulSet
→ vllm-0-1、vllm-0-2、vllm-0-3...
vllm-1 leader
→ vllm-1 worker StatefulSet
→ vllm-1-1、vllm-1-2、vllm-1-3...
因此,一组实际的资源关系可以理解为:
LeaderWorkerSet/vllm
├── StatefulSet/vllm # leader StatefulSet
│ └── Pod/vllm-0 # leader pod
│
└── StatefulSet/vllm-0 # worker StatefulSet for group 0
├── Pod/vllm-0-1
├── Pod/vllm-0-2
├── Pod/vllm-0-3
├── Pod/vllm-0-4
└── Pod/vllm-0-5
这也是为什么在检查资源时,会看到类似下面的结果:
kubectl get sts
NAME READY AGE
vllm 1/1 4h32m
vllm-0 5/5 3h38m
这里的 vllm 是 leader StatefulSet,vllm-0 是 group 0 对应的 worker StatefulSet。从这个角度看,LWS 可以理解为:用 Kubernetes 原生 StatefulSet 组合出来的分布式推理副本系统。它给上层用户暴露的是 LeaderWorkerSet 这个更贴近 AI 推理语义的资源;而在底层,仍然借助 StatefulSet 提供稳定身份、Pod 编号和生命周期管理能力。
3. Leader 和 Worker 如何协同
在本文实践中,LWS 被用于部署一个基于 Ray + vLLM 的多节点推理服务。整体逻辑是:
Leader Pod:
启动 Ray head
等待 worker 注册
启动 vLLM OpenAI API Server
Worker Pod:
启动 Ray worker
连接 leader Pod 中的 Ray head
参与分布式推理
leader Pod 的启动命令大致可以拆成两部分:
bash /workspace/multi-node-serving.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE)
python3 -m vllm.entrypoints.openai.api_server
--port 8080
--model /workspace/model/Qwen3-32B
--tensor-parallel-size 4
--pipeline_parallel_size 1
第一部分负责启动 Ray head,并等待所有 worker 加入。这里的 $(LWS_GROUP_SIZE) 是 LWS 自动注入的环境变量,表示当前 group 中的 Pod 总数。
第二部分在 Ray 集群 ready 后,启动 vLLM OpenAI API Server,对外提供 /v1/models 和 /v1/chat/completions 等接口。
worker Pod 的启动命令则更简单:
bash /workspace/multi-node-serving.sh worker --ray_address=$(LWS_LEADER_ADDRESS)
这里的 $(LWS_LEADER_ADDRESS) 也是 LWS 注入的环境变量,表示当前 group 内 leader Pod 的访问地址。worker 启动后,会通过这个地址连接 Ray head,并注册为 Ray worker。因此,整个 group 的启动过程可以理解为:
1. LWS 创建 leader Pod 和 worker Pods
2. leader Pod 启动 Ray head
3. worker Pods 连接 leader 的 Ray head
4. leader 等待所有 worker 就绪
5. leader 启动 vLLM OpenAI API Server
6. 外部请求进入 leader,由 vLLM / Ray 协调分布式推理
这种模式的好处是,Kubernetes 负责组级生命周期,Ray 负责组内分布式执行,vLLM 负责模型推理服务。三者分工比较清晰:
LeaderWorkerSet:
负责 Kubernetes 层面的组编排
Ray:
负责组内分布式运行时和 worker 管理
vLLM:
负责模型加载、推理执行和 OpenAI API 服务
4. 请求链路:从用户请求到分布式推理
部署完成后,外部请求通常只需要访问leader Pod暴露出来的服务端口。一条请求的链路可以理解为:
Client / Gateway
↓
Kubernetes Service
↓
Leader Pod
↓
vLLM OpenAI API Server
↓
Ray Head
↓
Ray Workers
↓
多卡 / 多节点分布式推理
从外部调用方视角看,它访问的仍然是一个标准 OpenAI 兼容接口,但在集群内部,这个请求实际会被 leader 协调到多个 worker 所在的 GPU 上共同完成。可以用下面的结构理解:
用户 / 应用
↓ HTTP / OpenAI API
Kubernetes Service
↓
Leader Pod: vllm-0
├── vLLM API Server
└── Ray Head
↓
├── Worker Pod: vllm-0-1
├── Worker Pod: vllm-0-2
├── Worker Pod: vllm-0-3
├── Worker Pod: vllm-0-4
└── Worker Pod: vllm-0-5
在这个模式下,Service 通常只需要选择 leader Pod。因为真正对外提供 HTTP API 的是 leader,而 worker 更多是作为组内计算节点参与推理。例如,可以通过 label 只选中 leader:
selector:
leaderworkerset.sigs.k8s.io/name: vllm
role: leader
这样,外部流量不会直接打到 worker Pod,而是统一进入 leader,再由 leader 内部通过 Ray 和 vLLM 协调分布式推理。
5. 为什么 LWS 适合多机推理
LWS 适合多机推理,并不是因为它本身提供了模型并行能力,而是因为它把“多 Pod 组成一个推理副本”这件事变成了 Kubernetes 可以理解的对象。对于大模型推理来说,一个 group 内的 Pod 需要具备几个特点:
第一,Pod 需要一起创建。
leader 和 worker 必须同时存在,否则 Ray 集群无法完整初始化。
第二,Pod 需要一起更新。
如果只更新 leader,不更新 worker,或者只更新部分 worker,就可能导致镜像版本、启动脚本、模型路径、运行参数不一致。
第三,Pod 需要一起重启。
在分布式推理中,一个 worker 异常可能会破坏整个 group 的一致性。与其尝试局部修复,不如按组重建,保证 leader / worker 状态重新对齐。
第四,扩缩容需要以组为单位。
一个大模型副本可能需要 6 个 Pod 或更多 Pod 才能运行。扩容时需要增加的是完整 group,而不是随机增加一个 worker。
LWS 正是围绕这些需求设计的。它支持 group 级滚动更新、group 级扩缩容、all-or-nothing restart,以及可选的拓扑感知放置能力。因此,它更适合那些“一个服务副本由多个 Pod 协同组成”的 AI 推理场景,而不是普通的无状态 Web 服务。
典型场景包括多节点 vLLM 推理。对于较大的模型,单机 GPU 资源可能无法完整承载模型权重或满足性能需求,因此需要将模型切分到多个 GPU、多个节点上运行。此时,一个完整的推理副本通常由一个 leader Pod 和多个 worker Pod 组成,leader 负责对外提供 API 服务并协调分布式运行,worker 则参与模型分片加载和推理计算。LWS 可以把这一组 Pod 作为一个整体管理,避免 leader 和 worker 在生命周期上被割裂。
另一个典型场景是基于 Ray 的 leader / worker 架构。Ray head 通常运行在 leader Pod 中,Ray workers 运行在 worker Pods 中。只有当 head 和所有 worker 都正常启动并完成注册后,这个推理副本才算真正可用。LWS 提供的组级生命周期管理,正好契合这种运行模式:组内 Pod 一起创建、一起更新、异常时按组恢复,而不是把每个 Pod 当成独立副本处理。
对于在线推理服务,LWS 的 group 级滚动更新也很有价值。模型镜像、启动参数、模型路径、推理引擎版本或运行时依赖发生变化时,不能只更新其中某一个 Pod,否则很容易出现 leader 和 worker 版本不一致、参数不一致或状态不一致的问题。LWS 以 group 为单位滚动更新,更符合分布式推理副本的实际运行边界。
在自动扩缩容场景中,LWS 也比普通 Deployment 更贴近多机推理的需求。HPA 或 KEDA 触发扩容时,真正需要增加的不是一个孤立 Pod,而是一整组可以独立承载推理请求的 leader + workers。LWS 暴露 scale 子资源后,HPA 调整的是 group 数量,这意味着扩容出来的是完整推理副本,而不是破坏现有分布式结构的单个 worker。
因此,LWS 的适用边界可以概括为一句话:当一个 AI 推理服务的最小运行单元已经不再是单个 Pod,而是一组必须协同工作的 Pod 时,就应该考虑使用 LeaderWorkerSet 来表达和管理这个工作负载。
6. 组级滚动更新:降低在线推理中断风险
对于在线推理服务来说,滚动更新非常重要。模型服务升级、镜像更新、运行参数调整,都不应该直接导致服务整体不可用。普通 Deployment 的滚动更新是以 Pod 为单位进行的,而 LWS 的滚动更新是以 group 为单位进行的。这意味着,一个 group 内的 leader 和 worker 会作为整体一起更新,而不是只更新其中一部分。
LWS 支持通过 maxUnavailable 和 maxSurge 控制滚动更新节奏:
spec:
rolloutStrategy:
type: RollingUpdate
rollingUpdateConfiguration:
maxUnavailable: 2
maxSurge: 2
replicas: 4
其中,maxUnavailable表示更新过程中允许不可用的 group 数量。maxSurge表示更新过程中允许额外创建的 group 数量。这和普通 Deployment 的滚动更新思想类似,但对象从单个 Pod 变成了 group。对于大模型推理来说,这一点尤其重要。因为一个 group 内的 Pod 必须保持一致,不能让 leader 用新镜像、worker 仍然用旧镜像,也不能让部分 worker 已经切换参数、部分 worker 仍然使用旧配置。因此,LWS 的滚动更新更符合分布式推理服务的实际运行逻辑:更新单位不是 Pod 而是一整组分布式推理副本
需要注意的是,部分滚动更新能力依赖 Kubernetes feature gate。例如在使用 maxUnavailable 相关能力时,需要确认集群版本和 StatefulSet feature gate 是否满足要求。否则,实际行为可能退化为更保守的逐个 Pod 更新方式。
7. Scale 子资源:让 HPA 可以扩缩 LWS
LWS 的另一个关键能力是提供 scale subresource。这意味着 HPA 可以像扩缩 Deployment 一样,动态调整 LeaderWorkerSet 的 replicas。但这里的 replicas 表示的不是普通 Pod 副本数,而是 group 数量。
例如:
replicas: 1
表示 1 个分布式推理 group
replicas: 2
表示 2 个分布式推理 group
如果每个 group 包含 1 个 leader 和 5 个 worker,那么:
replicas: 1
实际运行 6 个 Pod
replicas: 2
实际运行 12 个 Pod
这对于 AI 推理服务自动扩缩容非常关键。在前面自动扩缩容章节中,我们已经讨论过:AI 推理服务不应该只依赖 CPU / Memory,而应该更多结合 GPU 利用率、KV Cache、waiting queue、InferencePool queue 等指标。
当这些指标通过 Prometheus Adapter 或 KEDA 接入 HPA 后,HPA 就可以直接扩缩 LeaderWorkerSet:
scaleTargetRef:
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
name: vllm
这样,HPA 扩容时增加的是完整推理 group,而不是单个 Pod。对于多机推理来说,这比扩缩 Deployment 更符合实际需求。因为增加一个 worker 并不能形成新的服务能力;只有增加一整组 leader + workers,才代表新增一个完整可用的推理副本。


